AWS - Solution Design
In this group of live videos, we tackle a practical scenario to help you learn real-world cloud consulting skills.
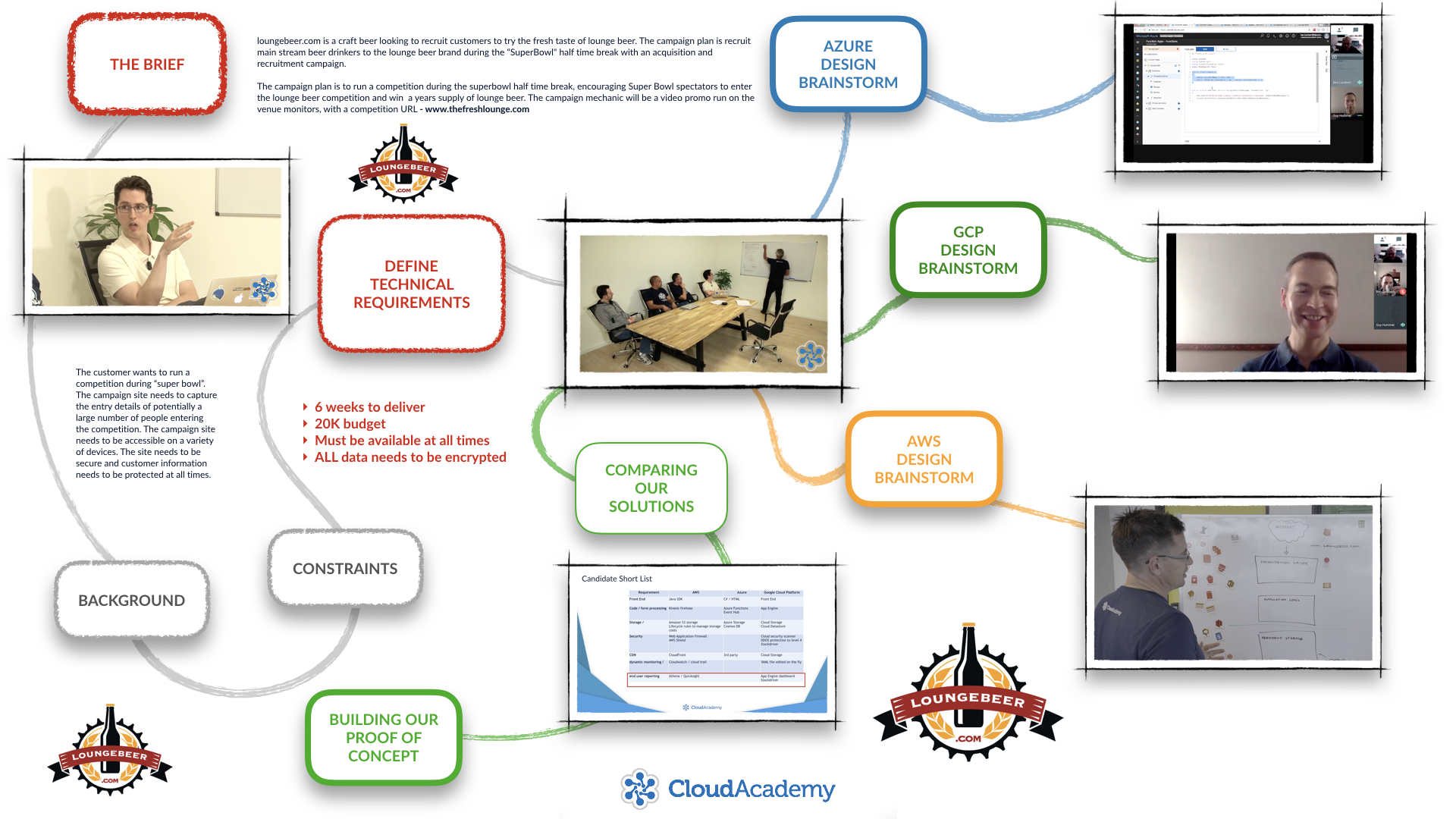
This is a unique and engaging live video format where we join the Cloud Academy AWS, Azure, and Google Cloud Platform teams in a real-time work situation. The team listen to a customer brief, discuss and define technical requirements and then evaluate which of the public cloud platforms could best deliver on the customer requirements.
From this course, you will learn how cloud professionals go about solving real-world business problems with cloud solutions.
With this course, you will learn how cloud professionals tackle and solve a business problem with each of the three public cloud platforms. This course is highly recommended for anyone interested in learning how to become a cloud architect, specialist or consultant!
Learning how to use your cloud skills in real-world situations is an important skill for a cloud professional. Real life projects require you to be able to evaluate requirements, define priorities and use your knowledge of cloud services to come up with recommendations and designs that can best meet customers' requirements. As a cloud professional you often have to think on your feet, process information quickly and be able to demonstrate design ideas quickly and efficiently.
In this course, we work through a customer scenario that will help you learn how to approach and solve a business problems with a cloud solution. The scenario requires us to build a highly available campaign site for an online competition run by loungebeer.com - a "craft" beer launching a new product in to the market at the US Superbowl event.
In these interactive discussions we join the team as they evaluate the business requirements, define the project constraints, and agree the scope and deliverables for the solution. We then work through the technical requirements we will use to evaluate how each of the three cloud platforms - Google Cloud Platform, AWS and Microsoft Azure - could be used to meet the technical requirements.
We follow each of the platform teams as they define solution architectures for Google Cloud Platform, AWS and Microsoft Azure. We then regroup to run a feature and price comparison before the team builds a proof of concept for our solution design.
This group of lectures will prepare you for thinking and reacting quickly, prioritzing requirements, discussing design ideas and coming up with cloud design solutions.
02/2018 - DynamoDB now supports encryption at rest so that would potentially influence our choice of database in thie scenario
https://aws.amazon.com/blogs/aws/new-encryption-at-rest-for-dynamodb/
For planning tools see
https://www.agilebusiness.org/content/moscow-prioritisation-0
http://www.allaboutagile.com/prioritization-using-moscow/
For more information on White Listing see
https://cloudacademy.com/course/understanding-aws-authentication-authorization-accounting/authorization-in-aws-1/
Andrew is fanatical about helping business teams gain the maximum ROI possible from adopting, using, and optimizing Public Cloud Services. Having built 70+ Cloud Academy courses, Andrew has helped over 50,000 students master cloud computing by sharing the skills and experiences he gained during 20+ years leading digital teams in code and consulting. Before joining Cloud Academy, Andrew worked for AWS and for AWS technology partners Ooyala and Adobe.