![]()
One of the common problems dealing with RESTful APIs is to choose where and how to aggregate resource data coming from different endpoints, even different services. Let’s say we have two endpoints on a service that manages surveys:
- One endpoint exposes a resource called SurveyInfo that contains the survey’s descriptive fields: title, description, number of questions, and so on.
- On the other, we can get a list of SurveyResult: a resource that exposes, for a specific user and survey, the given answers plus the information if he has completed that survey or not.
Our client needs to display the name and number of survey questions, contained in the SurveyInfo, along with his completion info, contained in the SurveyResult:
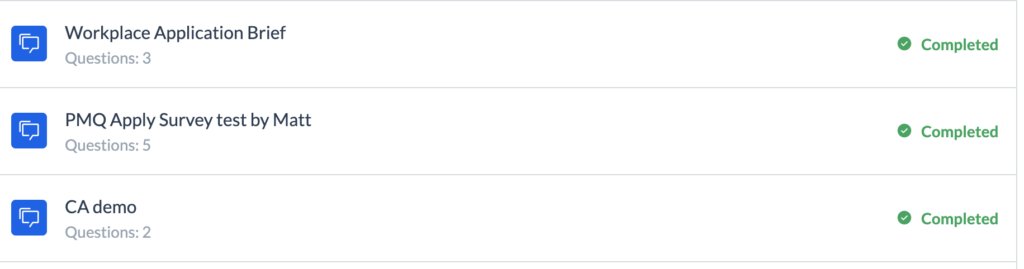
How can we compose them?
It can be done on the client side. It should know both the endpoints, call the one for retrieving the list of SurveyResult, collect the survey ids, and use these for retrieving the list of related SurveyInfo. Then, perform some aggregation logic based on the survey id they have in common. It seems an effective and simple solution but has drawbacks:
- This is business logic that shouldn’t stay in the presentation layer, where it’s hard to trace errors and easy to lose overall comprehension of the business domain.
- It requires two requests over the internet for something that can be done on the back end with a simple database query or some local network call.
- Endpoints need to be publicly available, increasing the risk of a data breach.
On the other side, making the aggregation on the back end often means inventing a new composite resource just for the sake of presenting data, thus increasing the number of endpoints to maintain for each possible permutation. In this case, we can just expose a new SurveyResultWithInfo resource, but what if we also need to show information about the user or the company that has created the survey? How many different composite resources and endpoints do we have to manage?
Looking at the problem from the opposite point of view, we can think to enrich the SurveyResult or the SurveyInfo resource with all the additional required data. This reduces the number of endpoints, but it increases the size of the response and it complicates the needed computations. Also for the cases, we don’t need to retrieve the other pieces of information.
For small projects, we can implement some data-shaping technique or it can be enough to find a trade-off between all these techniques, using the one the most fits our needs. But we are a growing company that manages big enterprise products, and we need to find a third way.
Our choice: the GraphQL Gateway
Implementing an API gateway is our way: a new actor is introduced between clients and services, and acts as an orchestrator that can analyze the request, call the needed endpoints and compose the requested data to be returned as a single response.
An API gateway hides the complexity of the underlying services and can offer coherent APIs that can be further customized to meet the needs of each type of client we are serving (smartphone app, web browser, tablet app). It still requires network calls to retrieve data, but it’s local to the required services, and it publicly exposes its endpoints while services remain hidden.
We might still worry about moving orchestration logic outside the services, but now we have a dedicated actor for that, and it still something on the back end side. In addition, one of the main benefits is that it can perform a protocol translation: our service endpoints are still RESTful, but we decide to adopt GraphQL as a protocol to query our gateway in a more flexible way.
It’s not the aim of this article to dive into what GraphQL is; there are lots of tutorials on the official page explaining the basics of a server-side implementation with the most popular programming languages. We have chosen to attempt this with Python and Graphene, a popular library for building GraphQL APIs.
Unfortunately, there is a lack of documentation on how to solve one of the most common GraphQL performance pitfalls: the N+1 problem. I hope this article will make life easier for those who want to solve it on the same stack.
The N+1 problem
Recall the SurveyInfo and the SurveyResult resources. This is how we define the related GraphQL object types on Graphene.
# Query to retrieve a survey info
class SurveyInfo(graphene.ObjectType):
id = graphene.ID()
name = graphene.String()
title = graphene.String()
duration = graphene.Int()
description = graphene.String()
steps_count = graphene.Int()
# Query to retrieve a survey result
class SurveyResult(graphene.ObjectType):
survey_id = graphene.ID()
slug = graphene.String()
is_completed = graphene.Boolean()
# other fields omitted for clarity
# Query to retrieve a list of survey results
class SurveyResultList(graphene.ObjectType):
items = graphene.List(SurveyResult)
count = graphene.Int()
With the above definitions, a client can ask for a list of SurveyResult but still needs to make a separate query for retrieving the related SurveyInfo. With Graphene, it is very easy to permit optionally receiving the SurveyInfo as part of a SurveyResult item. First, we need to add a SurveyInfo field as part of the SurveyResult definition:
class SurveyResult(graphene.ObjectType):
survey_id = graphene.ID()
slug = graphene.String()
is_completed = graphene.Boolean()
info = graphene.Field(type=SurveyInfo, resolver=SurveyInfoFromResultResolver.resolve) # SurveyInfo addition
Second, we need to instruct Graphene on how to resolve that field based on the retrieved SurveyResult. This is why we need to specify a resolver function (SurveyInfoFromResultResolver.resolve) that, on a first try, can be implemented to just perform a call to the SurveyInfo endpoint.
class SurveyInfoFromResultResolver(AbstractResolver):
@staticmethod
async def resolve(survey_result, info: ResolveInfo) -> Promise:
survey_id = survey_result.survey_id
# Here I get the survey info from the related endpoint
survey_info = RestHttpClient.get_survey_info(survey_id)
return survey_info
Does it work? Sure, but it also represents a way to originate the performance issue of the N+1 problem! In fact, this function is called for each item of the SurveyResultList we are retrieving!
This means, for instance, that if we retrieve 10 items then 10 network calls are made. This is why we talk about the “N+1” problem: 1 call for retrieving the list of SurveyResult plus N calls to the SurveyInfo endpoint for each item in the list.
How can we solve it? If our REST service exposes an endpoint that can accept a list of survey ids and return a list of SurveyInfo, we can think of collecting all the survey ids from each SurveyResult and perform just one call with them. But the resolver function is still called N times, and there is no way to instruct Graphene to call it just once. Instead, there is an “official” solution based on an object called “DataLoader.”
Data Loaders
In every GraphQL implementation, resolver functions are enabled to return either the resolved data or a Promise (i.e. an object that tells that the data will be retrieved later). When the promise is resolved, Graphene will complete the response with the “promised” data.
This is the “trick” behind DataLoaders: they are objects that, when asked to load a resource with a particular identifier, return just a promise for that resource and, under the hood, collect all the requested identifiers to perform a single batched request.
This is how the resolver function looks after the introduction of a DataLoader:
class SurveyInfoFromResultResolver(AbstractResolver):
@staticmethod
async def resolve(parent, info: ResolveInfo) -> Promise:
survey_id = parent.survey_id
# here I get the data loader instance
survey_info_data_loader = info.context["request"].state.survey_info_loader
# I ask the data loader to batch the request for this survey_id
# No http calls is actually performed, it just return a Promises that will be resolved later.
survey_info_load_promise = survey_info_data_loader.load(survey_id)
return survey_info_load_promise
No more calls to the REST endpoint are performed in the resolution function: each call to the load method of the DataLoader simply means “collect this id for later.” The DataLoader will batch all the survey ids and will call the batch resolution function that, by requirements, we have to define on the DataLoader itself with the name batch_load_fn:
class SurveyInfoLoader(DataLoader):
def __init__(self, headers):
super().__init__()
self.http_client = SurveyClient()
@rollbar_trace
def batch_load_fn(self, survey_ids):
try:
# retrieving the list of survey infos using the batched survey ids
get_survey_info_response = self.http_client.get_survey_infos(survey_ids)
# reordering the retrieved infos to match the the order of the survey_ids list
retrieved_items = get_survey_info_response.items
ordered_survey_infos = []
for survey_id in survey_ids:
survey_info = next((item for item in retrieved_items if item.id == survey_id), None)
ordered_survey_infos.append(survey_info)
return Promise.resolve(ordered_survey_infos)
There is no need to worry about “when” this function will be called: it’s guaranteed that it will be done after all the survey ids are collected. We just need to ensure that these two requirements are satisfied:
- The items retrieved on the batch function must be reordered to match the same order of the related identifiers. That is, if the batch load receive survey ids “1,” “4,” and “6,” we have to return SurveyInfo items related to survey ids “1,” “4,” and “6” exactly in this order.
- The data loader should be instanced once for each request. More complex caching and batching strategies can be performed with a DataLoader that has a lifetime that spans multiple requests, but it’s something beyond the scope of this article.
There are different ways to satisfy the second requirement, regarding which stack of libraries are used to implement GraphQL. If possible, the recommended one is to instance a new DataLoader before each GraphQL query execution and place it as part of the execution context to be available on the resolver functions. On our gateway, we use FastAPI and a “ready to go” GraphQL app implementation from the Starlette library. Unfortunately, this implementation hides the access to the execution context, so we had to find another way.
Starlette offers the chance to add data on an incoming request on its state property. Since the request can be retrieved in the resolver functions through the execution context, we can plug a simple starlette middleware that intercepts the request and adds a new DataLoader instance on its state:
# this instruct DataLoader Promises to work on the same event loop of the GraphQLApp
# (Asyncio since the GraphQL app is using the AsyncioExecutor)
set_default_scheduler(AsyncioScheduler())
class DataLoadersMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request, call_next):
# every time a new request is created a new SurveyInfoLoader is added in the request state.
# Note that adding per request objects to the request.state is the recommended way following the
# starlette documentation
request.state.survey_info_loader = SurveyInfoLoader(request.headers)
response = await call_next(request)
return response
app = FastAPI(title='GraphQLTutorial', description='CloudAcademy GraphQL server')
app.add_middleware(DataLoadersMiddleware)
app.add_route(
"/graphql/",
GraphQLApp(
schema=graphene.Schema(mutation=Mutation, query=Query),
graphiql=ENABLE_GRAPHIQL,
executor_class=AsyncioExecutor,
),
)
Conclusion
Although we have shown how to use DataLoaders on a Python app, they were originally developed by Facebook for the Javascript implementation of GraphQL, and it seems they were ported on each officially supported programming language.
They are simple but powerful objects. They use the best parts of GraphQL, enabling flexible composition of resources without too much compromising on the performance side. Plus, they are easy to use.
We are currently switching our gateway to Apollo/Typescript in order to exploit GraphQL on a better-supported stack. Also if it’s not in your plans to use Graphene, understanding the concept behind DataLoaders is worth the effort!