![]()
The Cloud Academy training platform offers a Skill Assessment tool capable of providing useful insights to learners and their managers. The assessment of skills is based both on the capability of users in solving practical exercises (hands-on labs) and on their proficiency in answering theoretical multiple-choice questions (quizzes and exams). The effectiveness of such a tool is based upon an accurate calibration of the hands-on labs and the exams the user is required to take.
In a previous post, we presented some of the ways in which Cloud Academy uses Natural Language Processing (NLP). In this article, we will show how NLP can be used for calibrating the multiple-choice questions (MCQs) of quizzes and exams as soon as they are created, which consists of estimating some properties (referred to as latent traits) that are required for scoring students under assessment. The immediate consequence of this solution will be an increased capability of assessing the users’ scores also with brand new questions, that typically require data (and time) before being usable.
In this article, we will describe a novel approach for estimating the latent traits of MCQs from textual information. This approach, named R2DE (Regression for Difficulty and Discrimination Estimation), is the result of an ongoing collaboration between Cloud Academy and Politecnico di Milano and will be presented in the research paper “R2DE: a NLP approach to estimating IRT parameters of newly generated questions” at the forthcoming International Conference on Learning Analytics and Knowledge (LAK ‘20). The paper is already available online.
What are latent traits and why are they important?
Latent traits are numerical values describing some properties of a question, and they can be of different kinds. In this post, we will focus on two latent traits that are used for assessing learners’ skills: the difficulty and the discrimination. Assuming the student’s knowledge can be represented on a numeric scale, referred to as skill, the difficulty level represents the skill level required in order to have a 50% probability of answering the question correctly. The discrimination, instead, indicates how rapidly the odds of correct answer increase or decrease with the skill level of the student.
In order to clarify the effects of difficulty and discrimination, some images can be helpful. Specifically, we display here some functions (named item response functions), which represent how the probability of correct answer varies depending on the student’s skill level and the question’s latent traits. In all these images the horizontal axis represents the skill level of the student and the vertical axis represents the probability of correct answer.
There is no theoretical limit to the difficulty nor to the discrimination of a question, but a common approach consists in considering the difficulties in the range [-5; +5], and we assume discrimination in [-1; 2.5]. We show here the item response function of a question with difficulty 0.0 and discrimination 1.0. It is important to remark here that both difficulty and discrimination are dimensionless measures (i.e., they do not have a unit of measurement). A difficulty of 0.0 is an “average” difficulty (not very easy, not very hard), and similarly, a discrimination of 1.0 is a typical value.
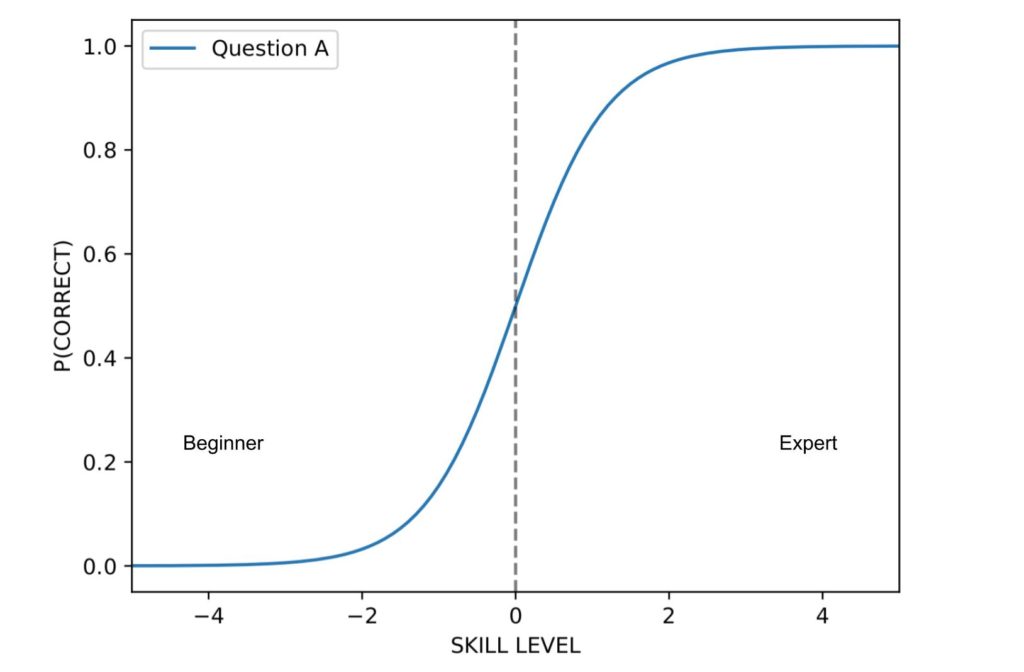
Students with a very low skill level are on the left-hand side of the plot (i.e., skill value smaller than 0) and have a very low probability of answering correctly. On the other hand, skilled students are positioned on the right end side of the plot, and are likely to select the correct choice. The curve is centered in 0 because that is the value of question A’s difficulty; the curve for more difficult questions would be positioned towards the right-hand side of the plot, and for easier questions towards the left-hand side.
Difficulty and discrimination
For the readers who wish to better understand such concepts, have a look at the image below that shows how the probability of correct answer changes depending on difficulty and discrimination. Specifically, the image plots the probability for three questions:
- The same question presented above, with difficulty 0 and discrimination 1
- A more difficult question, with difficulty 2, and the same discrimination 1
- An easier (difficulty -3) less discriminative question, with discrimination 0.25
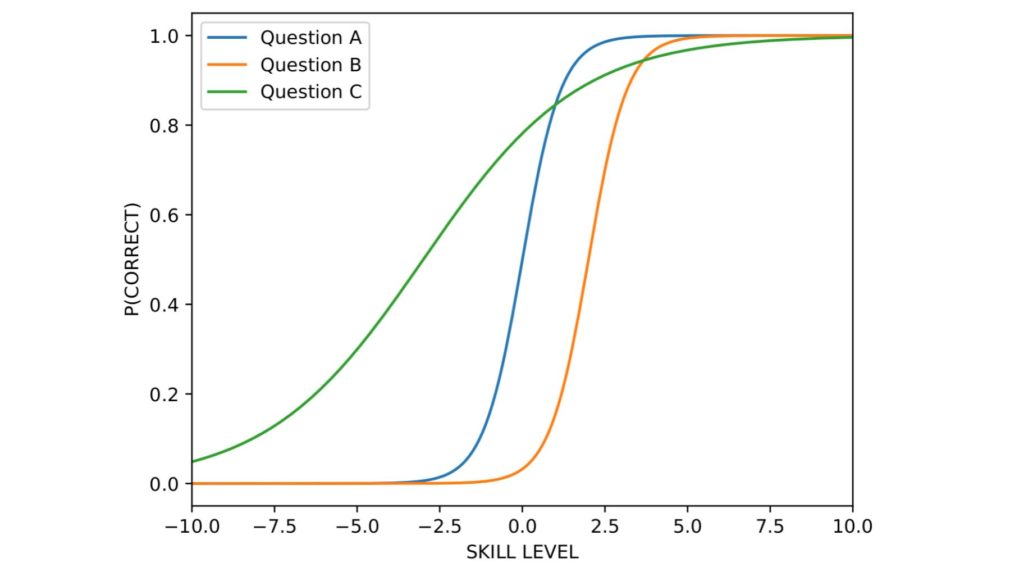
It can be seen that only highly skilled students have a high probability of correctly answering the most difficult question (question B), while the other students are unlikely to pick the correct choice. Lastly, the plot of question C shows that questions with low discrimination provide less information for assessing the students, as students with different skill levels have a similar probability of answering correctly. Indeed, questions with low discrimination are often “anomalous”: for instance containing errors in the text, or being worded poorly, or even being not related to the topic assessed by the exam.
From this quick overview on the impacts of difficulty and discrimination, it can be understood the importance of an accurate estimation of questions’ latent traits: indeed, it is useful not only to improve the accuracy of students’ assessment but also to identify (and thus fix or remove) the questions that are not suited for scoring. If you are interested in the details of how the questions’ latent traits are used to estimate students’ skill levels, you can have a look at our previous post about that.
Traditional techniques for question calibration
Latent traits are, by definition, unobservable variables that have to be estimated, a process which is named question calibration. Traditionally, it is performed with one of two techniques: either manually by human experts or with pretesting.
Manual calibration consists in having domain experts select the values of questions’ latent traits: this is very time consuming (unless done at creation time) and – most importantly – subjective, thus inconsistent and uncertain. Furthermore, while difficulty can be intuitively set, discrimination is not as intuitive.
On the other hand, pretesting consists of giving the question to a set of students (usually few hundred or few thousands) together with a set of other calibrated questions, but without using it for scoring them. The answers that are given by the students are leveraged to calibrate the question under pretesting. This approach leads to an accurate and fairly consistent calibration of newly generated questions but introduces a long delay between the time of question creation and the deployment of the question to score students.
The framework that we are going to introduce in the next sections is based on a Machine-Learning approach that can be used to provide an accurate and consistent initial calibration of newly-generated questions, in order to reduce the delays introduced by pretesting and avoid the inconsistencies of manual calibration.
R2DE: estimation of latent traits from text
In our research, we introduced R2DE, a machine learning-based technique to estimate the latent traits of newly-created multiple-choice questions from textual information. R2DE provides a method for performing a real-time calibration at the very moment of question generation, and this information can be immediately used to check whether the question satisfies all the quality criteria (e.g. discrimination above a certain threshold) and, if that is not the case, the question can be modified and fixed before being used to score students. At a later time, when the question is already being used in quiz sessions, its calibration can be fine-tuned by leveraging the students’ answers. We provide here an introduction to R2DE and some experimental results, the complete description, and outcomes can be found in the paper.
How does it work?
Given a MCQ, R2DE extracts from the text of the question and the text of the possible choices meaningful features, which are numerical values representing properties of the text, and uses such features for the estimation of difficulty and discrimination. Being a Machine Learning-based model, it requires some data to be trained upon: specifically, it requires a set of calibrated questions and their textual information. Calibrated questions are used as ground truth to train the model, which can then generalize and be used to infer the latent traits of previously unseen questions.
Conceptually, R2DE is made of two blocks which work in a pipeline: the first one performs the preprocessing of the text, in order to convert the textual information into feature arrays (basically, sequences of numbers representing the textual information of each question); the second one is made of two Machine Learning algorithms that are trained to estimate questions’ latent traits from the feature arrays.
Let’s start from pre-processing, which is done in several steps:
- Firstly, for each question, R2DE concatenates the text of all the possible options (both correct and wrong) to the text of the question, to create a single body of text.
- Then, it preprocesses all the input texts using standard steps of NLP: removal of stop words, removal of punctuation, and stemming.
- The third step consists in creating, for each question, a representation of the words that appear in the text (i.e., the feature array). This is done using a technique from Information Retrieval: TF-IDF (i.e., Term Frequency-Inverse Document Frequency). The TF-IDF weight represents how important a word (or a set of words) is to a document in a corpus. The importance grows with the number of occurrences of the word in the document but it is limited by its frequency in the whole corpus: intuitively, words that are very frequent in all the documents of the corpus are not important to any of them. Lastly, since the feature set produced as outcome of TF-IDF is too large to be directly used, we consider only the most frequent features (the number of features to consider is a parameter to learn while training the model).
The second block of R2DE is made of two Random Forests, which are trained using the feature arrays created by the previous block and the ground truth latent traits. Random forests are ensembles of decision trees and, in this case, the two forests are trained to estimate from the feature arrays the target difficulty and the target discrimination, respectively. The following image displays the complete architecture of R2DE.

Experimental results
We tested R2DE on a subset of calibrated questions coming from the Cloud Academy catalog. All the questions are MCQ and four possible choices are always presented to the student; the questions might have more than one correct answer and, if that is the case, the student is required to select all the correct choices. In order to test the estimation capabilities of R2DE, we divided the calibrated questions into two sets to train and evaluate the model: specifically, we consider 80% of the questions as training set and 20% as test set. With this approach, it is possible to train R2DE on the training questions and evaluate it on the test questions.
R2DE performs fairly well and is capable of estimating both the difficulty and the discrimination with small errors: specifically, we measured the Mean Absolute Error (MAE) of both difficulty and discrimination estimation, which represents the average difference between the ground truth latent traits and the estimated value. The MAE for difficulty estimation is 0.639 and the MAE for discrimination estimation is 0.329. Considering that the difficulty range is [-5; +5] and the discrimination range [-1; 2.5], these results show that R2DE is capable of providing an accurate calibration of newly-generated MCQ using as input only the text of the questions. In order to highlight the size of the error in the whole range, we also reported the Relative error, which is defined as the MAE divided by the size of the difficulty (and discrimination) range: specifically, we obtained a Relative MAE of 6.39% for difficulty estimation and 9.4% for discrimination estimation.
Conclusions
R2DE enables the calibration of multiple-choice questions at the moment of question generation, using only the text of the question and of the possible choices. Such an early calibration can be used to improve the quality of the questions that are used to assess the students and the time that is necessary to move from question generation to the deployment of a new question in the exams. We plan to include this functionality in our content editing tool to provide content curators immediate feedback about the difficulty and quality of questions they have just created.
R2DE resulted from an ongoing collaboration between Cloud Academy and Politecnico di Milano, and the paper which introduces R2DE will be presented at the International Conference of Learning Analytics and Knowledge. Unfortunately, due to current travel restrictions, the conference is confirmed but it will be held fully online; for any information about the conference, keep an eye on the website.
Feel free to reach out to comment below for any doubts or questions about the paper!