![]()
Cloud services offered via web API endpoints are an exploding and apparently relentless trend. The big players are exposing a huge (and increasing) spectrum of state-of-the-art technology, making it possible for developers all over the world to integrate it into their apps.
Clearly, the field of artificial intelligence and machine learning is no exception, claiming a huge share of the most high-tech functions exposed by vendors like Amazon, Google and Microsoft. Be it recognizing the content of images (see previous blog posts about the Google Vision API, Amazon Rekognition and a comparison of the two), the words spoken in a piece of recorded speech (Getting Started with Google Cloud Speech API) or crunching data using robust standard algorithm (Amazon Machine Learning: Use Cases and a Real Example in Python), it’s nowadays very quick and easy to get started with some ready-to-go solution where all the underlying complexity is conveniently hidden by the cloud.
In our recent post, we described our encounter with the Google Cloud Natural Language API. Let’s now have a second look at this service and compare it to Stanford CoreNLP, a well known suite for Natural Language Processing (NLP). We will discuss strengths and weaknesses of the two solutions, comparing which features are available and how to use them.
The Stanford CoreNLP suite
The Stanford CoreNLP suite is a software toolkit released by the NLP research group at Stanford University, offering Java-based modules for the solution of a plethora of basic NLP tasks, as well as the means to extend its functionalities with new ones. The evolution of the suite is related to cutting-edge Stanford research and it certainly makes an interesting comparison term.
CoreNLP is not a cloud-based service. Instead, it can be
- checked out on the http://corenlp.run/ Demo page or
- downloaded as a package (Java 1.8+ required; latest CoreNLP release 3.7.0 at the time of writing).
In the following we’ll focus on the second option.
The CoreNLP suite can be accessed via command line, via the native Java programmatic API, or deployed as a web API server.
For the sake of coding language freedom, we’ll stick with the server option. The examples will be based on the pycorenlp Python client, but many other clients exist for the most popular languages.
CoreNLP installation
First, let’s set the CoreNLP server up. We just need to go through a few steps:
- If you don’t have it already, install the JDK, version 1.8 or higher
- Download the stanford-corenlp-full zip file and unzip it in a folder of your choice
- From within that folder, launch
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer [port] [timeout]
If no value is provided, the default port is 9000.
Now, let’s check if everything went well: assuming the default configuration, you should be able to reach page http://localhost:9000 on your machine and see an interface like this
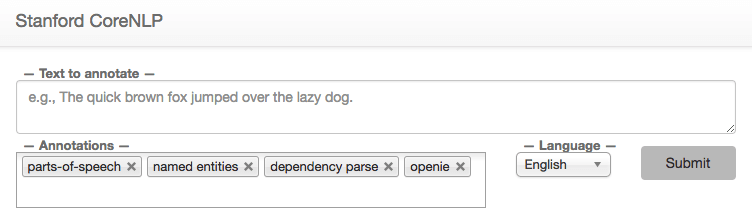
From there, you can already start playing around and submit small texts to the CoreNLP engine through the provided User Interface. The CoreNLP server runs the NLP analysis and graphically shows the results.
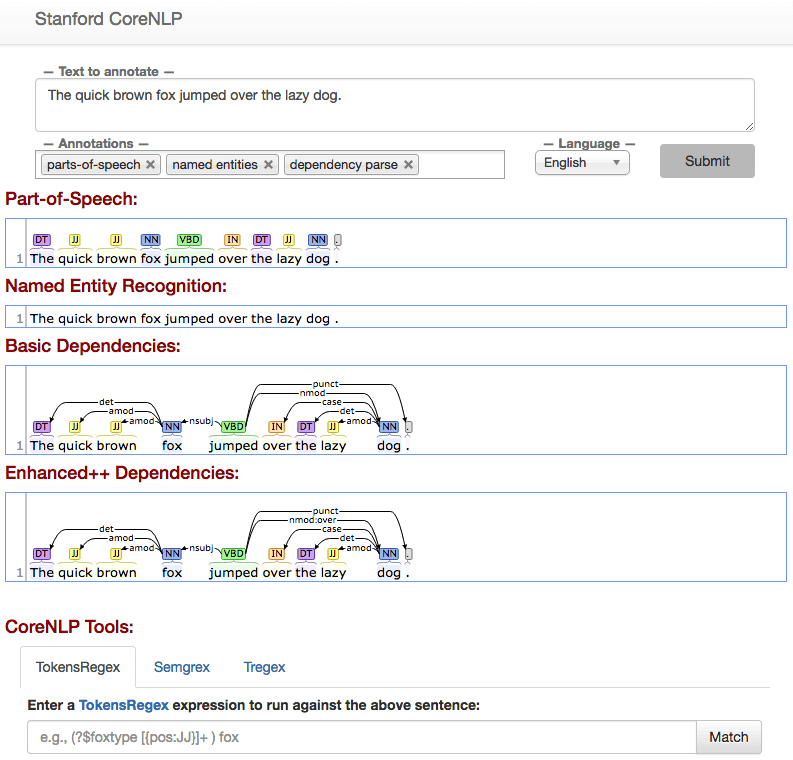
Submit an analysis via code
It’s time for our first call to the server via code. First, we need to make sure we have the needed libraries in the requirements (e.g., to be added to the requirements file and installed through pip), i.e.,
# requirements.txt pycorenlp==0.3.0
Second, we can use the following, very simple snippet of code, to send the first piece of text to our local CoreNLP server.
from pprint import pprint
from pycorenlp.corenlp import StanfordCoreNLP
host = "http://localhost"
port = "9000"
nlp = StanfordCoreNLP(host + ":" + port)
text = "Joshua Brown, 40, was killed in Florida in May when his Tesla failed to " \
"differentiate between the side of a turning truck and the sky while " \
"operating in autopilot mode."
output = nlp.annotate(
text,
properties={
"outputFormat": "json",
"annotators": "depparse,ner,entitymentions,sentiment"
}
)
pprint(output)
Only a few parameters are needed:
- Clearly, the text to analyze.
- The output format for your analysis results. In this case, we chose a JSON output.
- A list of annotators keywords, defining the ways you want the text to be analyzed or annotated (i.e., the NLP tasks to be performed on it). In this snippet we are asking for basic grammar/syntax analysis (depparse), entity extraction (ner and entitymentions) and sentiment polarity detection (sentiment).
For a comprehensive description of all options, have a look at the official documentation (particularly the CoreNLP server guide and the available annotators overview).
After launching the code, the server might take a few seconds (the very first analysis launched on a fresh server instance requires to bootstrap the chosen annotators). When the analysis is finished the server returns a JSON result of this type.
{
'sentences': [
{
'basicDependencies': [
{
'dep': 'ROOT',
'dependent': 7,
'dependentGloss': 'killed',
'governor': 0,
'governorGloss': 'ROOT'
},
{
'dep': 'compound',
'dependent': 1,
'dependentGloss': 'Joshua',
'governor': 2,
'governorGloss': 'Brown'
},
…
],
'enhancedDependencies': [
{
'dep': 'ROOT',
'dependent': 7,
'dependentGloss': 'killed',
'governor': 0,
'governorGloss': 'ROOT'
},
{
'dep': 'compound',
'dependent': 1,
'dependentGloss': 'Joshua',
'governor': 2,
'governorGloss': 'Brown'
},
...
],
'enhancedPlusPlusDependencies': [
{
'dep': 'ROOT',
'dependent': 7,
'dependentGloss': 'killed',
'governor': 0,
'governorGloss': 'ROOT'
},
{
'dep': 'compound',
'dependent': 1,
'dependentGloss': 'Joshua',
'governor': 2,
'governorGloss': 'Brown'
},
...
],
'entitymentions': [
{
'characterOffsetBegin': 0,
'characterOffsetEnd': 12,
'docTokenBegin': 0,
'docTokenEnd': 2,
'ner': 'PERSON',
'text': 'Joshua Brown',
'tokenBegin': 0,
'tokenEnd': 2
},
{
'characterOffsetBegin': 14,
'characterOffsetEnd': 16,
'docTokenBegin': 3,
'docTokenEnd': 4,
'ner': 'NUMBER',
'normalizedNER': '40.0',
'text': '40',
'tokenBegin': 3,
'tokenEnd': 4
},
...
],
'index': 0,
'parse': ...,
'sentiment': 'Negative',
'sentimentValue': '1',
'tokens': [
{
'after': ' ',
'before': '',
'characterOffsetBegin': 0,
'characterOffsetEnd': 6,
'index': 1,
'lemma': 'Joshua',
'ner': 'PERSON',
'originalText': 'Joshua',
'pos': 'NNP',
'word': 'Joshua'
},
{
'after': '',
'before': ' ',
'characterOffsetBegin': 7,
'characterOffsetEnd': 12,
'index': 2,
'lemma': 'Brown',
'ner': 'PERSON',
'originalText': 'Brown',
'pos': 'NNP',
'word': 'Brown'
},
...
]
}
]
}
You can note a similarity between this output and the one returned by Google Natural Language (see our first post about NLP with Google API for a review of the basic concepts).
Let’s see where we can find the desired information:
- Grammar and syntax information. These are contained in the “tokens” section and in the “Dependencies” sections (“basic”, “enhanced” and “enhancedPlusPlus”, see the Stanford typed dependencies manual and the Enhanced Dependencies reference for details on their differences).
- Named entity recognition. Information on relevant entities is provided in the “tokens” section, under the “ner” attribute, and more concisely in the “entitymentions” section.
- Sentiment polarity. The “sentiment” attribute expressed the polarity sign (including the possibility of Neutral), with a corresponding numeric value in “sentimentValue” (high values for positive sentiment).
With this analysis at our disposal, we make a few experiments to qualitatively compare the Google Natural Language API and the Stanford engine. Our analysis is limited to a few sample texts we submitted to both the NLP tools and cannot provide an exhaustive comparison.
Feature comparison
For the sake of our qualitative comparison, we’ll use the same text from ABC news that we chose when testing the Google Natural Language API, i.e.:
“Joshua Brown, 40, was killed in Florida in May when his Tesla failed to differentiate between the side of a turning truck and the sky while operating in autopilot mode.”
We can proceed category by category.
Grammar and syntax
Both engines seem to work well. Dependency tree conventions are a bit different but mostly equivalent.
Entity extraction
The entity extraction behaves as expected for both services, being able to detect the main entities such as: Joshua Brown, Florida, and Tesla.
Stanford also retrieves the number 40 and recognizes the month May, which might be very useful for several applications. However, Tesla is assigned the type PERSON. The Google API, in turn, classify Tesla as an ORGANIZATION (a bit better) but misses May as a DATE.
One plus for Google in this case is the ability to link recognized entities to their Wikipedia page with quite good disambiguation capabilities. This task is backed by Google’s humongous (and presumably ever-evolving) knowledge base, and is likely to get even better in the future.
Stanford CoreNLP also provides similar feature, allowing to perform entity linking of detected entities to their Wikipedia page. Qualitative tests suggest that the accuracy of Google’s disambiguation capabilities for this task are better. One more drawback comes from the fact that a separate model file is needed for this feature (the english-models-kbp from CoreNLP Github page), and its requirements are quite demanding in terms of memory.
Sentiment analysis
The sentiment analysis correctly detects a “negative” for this text in both engines. By default, CoreNLP returns only the sentiment class, while Google also provides two real numbers for polarity and magnitude. Both analyses show a separate sentiment value for all sentences in the text, but CoreNLP does not aggregate them in a single overall score.
As a comparison with our earlier sentiment experiment with Google, we can increasingly remove polarity-relevant words from the input text and see how the CoreNLP analysis changes.
| Input text | Returned sentiment (CoreNLP) |
| 1. Removed “killed” Joshua Brown, 40, was in Florida in May when his Tesla failed to differentiate between the side of a turning truck and the sky while operating in autopilot mode. |
“Negative” (score: 1) |
| 2. Removed “failed to” Joshua Brown, 40, was in Florida in May when his Tesla differentiate between the side of a turning truck and the sky while operating in autopilot mode. |
“Negative” (score: 1) |
3. Removed
Joshua Brown was in Florida when his Tesla differentiate between a turning truck and the sky. |
“Neutral” (score: 2) |
The Natural Language API returned “negative”, “positive” and “positive” for these inputs.
The first case is probably again correct for both providers. The other two tests are a bit more unclear.
“Negative” for case 2 is probably wrong, although “positive” is questionable, too.
“Positive” for case 3 can also be questioned. “Neutral” is probably not far from right.
Overall, this very quick test does not highlight any huge quality gap.
Extra features
CoreNLP exposes several interesting functions in addition to those we explored above. Such extra features consist of additional text annotators, offering functions that are not currently available on Google Cloud service. Let’s present in the following some of the most interesting ones.
Coreference annotator
Coreference resolution is the NLP task of identifying all words in a text that refer to the same entity, e.g. understanding that in
“Albert Einstein was a smart guy. He received his Nobel Prize in 1921.”
“Albert Einstein”, “he” and “his” all refer to the same person.
This capability is quite relevant, e.g., when trying to aggregate all available information about a specific entity in one or multiple texts, since references to that entity hidden behind a pronoun are easily lost (and in the example above we would know how smart Albert was but not when he won the Nobel Prize).
The task is not an easy one, and the Stanford CoreNLP suite offers the dcoref annotator to take care of it. Let’s have a look at some examples, either via code or via GUI (your local one or the online demo available for quick tests).
Text1: “John met Jane in 2013. He married her a few years later.” – the engine correctly retrieves the associations he → John, her → Jane, likely helped by the gender hints.
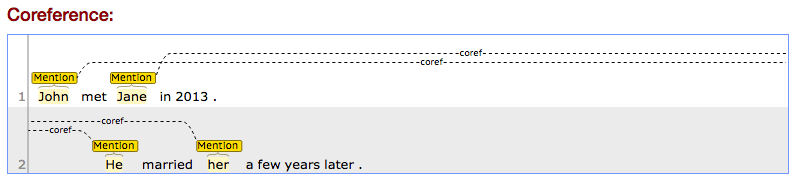
Text2: “Right now I’m testing CoreNLP and its features. It provides an annotator for coreference resolution.” – the task is not limited to person mentions, as seen here. “its” and “It” are correctly retrieved as co-referring and pointing to CoreNLP.
As said, the task is not trivial and it’s easy to come up with difficult or ambiguous cases.
Text3: “Right now I’m testing CoreNLP and its features. It’s always a pleasure to submit tricky texts.” – this use of “it” representing an entire (following) clause is one of the curses of coreference resolution, as in this case in which “CoreNLP” and “its” (correctly co-referenced) are also linked to “it” (wrong).
You can keep on testing the feature with other sentences such as:
- “Luke’s first master was Obi-Wan. He was a good teacher.” – involves semantics
- “The Chicago Bulls could count on Michael Jordan during their six winning seasons, and they are considered one of the strongest teams ever.” – plural pronoun
Or any new ones you might think of.
At the time of writing, Google Natural Language is not exposing a feature like this one. It would definitely be a nice add (and actually one we believe likely to appear at some point).
Cool Regex engines
A cool feature CoreNLP offers is a set of specialized regex engines, based not only on plain text but also on a specific parsing structure detected in the text itself (e.g. the dependency tree of a sentence). Available engines are TokensRegex, Semgrex and Tregex for matching patterns on tokens, on semantic relations and on parse trees, respectively. Although relying on different structures, the logic behind the three engines is similar. We show some examples of Semgrex usage, but more can be found in the documentation.
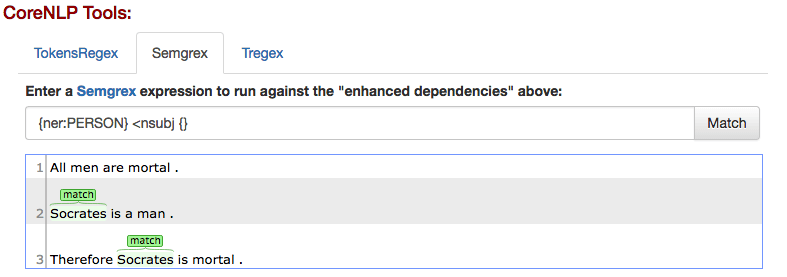
Semgrex is able to find portions of text matching a query related to the entity type or role of text tokens and/or their syntactical dependence on other tokens in the sentence. Example: let’s assume I want to identify all subjects in the sentence
“All men are mortal. Socrates is a man. Therefore Socrates is mortal.”
Semgrex allows to write the expression
{pos:NN}
to look for all nodes ({}-brackets are meant to represent the concept of node) whose part-of-speech is NN (singular common noun, in Stanford’s notation). This returns a match with “man”. It’s also possible to compose more complex conditions, e.g.,
[{pos:NN}|{pos:NNS}|{pos:JJ}]
to get common nouns (both singular and plural) and adjectives, thus obtaining “men”, “mortal”, “man” and again “mortal”.
As mentioned, it’s possible to retrieve nodes by their entity type. For example {ner:PERSON} returns the two instances of “Socrates”.
Even more interesting, expressions can involve more nodes, and the relation between them. If we look for
{} <nsubj {}
we get “men”, “Socrates” and “Socrates”, i.e. all nodes that are the subject of another node.
The two patterns can be combined, for example, to get all subjects that are also entities of type PERSON, with
{ner:PERSON} <nsubj {}
Which returns the two “Socrate”s only.
The patterns can be complicated in interesting and potentially very useful ways, allowing to precisely isolate the desired information with a simple high level language.
Conclusions
We enjoyed discovering the Stanford CoreNLP tool, one of the most popular NLP frameworks.
The features offered by CoreNLP are qualitatively comparable with those offered by Google, although the resources potentially available in a Cloud environment represent a huge advantage; indeed, in several experiments the entity extraction and syntax parsing of Google API slightly outperformed CoreNLP. As an example of this, the task of linking detected entities to their Wikipedia page shows how it’s possible to take advantage of continuous updates of a Cloud-based service, without the need to allocate one’s local resources to use it.
Still, CoreNLP showcases some very nice features that are missing in Google’s offering, and its language coverage is a bit wider (CoreNLP provides pre-trained models for English, Arabic, Chinese, German, French and Spanish out of the box, plus some community-made models, as opposed to English, Spanish and Japanese supported by Google).
To be kept in mind, the two engines are of markedly different origin: CoreNLP comes from academia, which means it prioritizes “novel” over “stable/business-reliable”, while Google aims at exposing a dependable service, possibly at the expense of leaving some cool features out of the picture (at least at present).
To summarize
You should go with StanfordCoreNLP if:
- For some reason you need to deploy a fully functional NLP system on your local machine
- You want to play with cutting-edge features that’s not necessarily easy to find in industrial NLP platforms, and that you can extend with custom modules
You should go with Google Natural Language API if:
- You want to take advantage of large, Google-scale computing structure and data
- You need a reliable/industrial-strength system
If we believe in the best embodiment of the academia-industry relationship, maybe we’ll see ideas flowing from one to the other to finally provide the most sophisticated AI and NLP features with industry-level stability.
We hope we have caught your interest (and maybe inspired you to explore the limits of both technologies on your own).