![]()
A new natural language processing API: Google is working hard to provide cloud services that facilitate human-computer interaction through tools that are able to consume human language.
In a recent blog post, we discussed Google Cloud Speech API, a service to convert audio speech to text. Probably driven by a similar technology based on deep neural networks (in particular, Tensorflow), Google recently released the Beta version of the Google Cloud Natural Language Processing API, a further brick of their machine learning architecture. Such service extracts meaning and structure from unstructured text. Specifically, the engine recognizes entities (people, organizations, locations, etc.), their syntax, made up by their logic role (noun, verb, adverbs, adjectives) and relations (the name the adjective refers to), and document polarity (positive, neutral, negative).
You can get a first look at its services and play around with some of the features at cloud.google.com/natural-language.To use the Natural Language Processing API, you can apply for a free trial and create an API key from the Google Cloud Platform’s API Manager.
Google’s natural language processing API and Python
The API exposes a RESTful interface that can be accessed via common POST HTTP requests. However, a multitude of clients is already available for several programming languages. In our tests, we experimented with the Python client, whose code can be retrieved on GitHub. To use the client, simply add the following entry to your requirements file:
# requirements.txt google-api-python-client==1.5.5
For instance, the following Python script defines a function to submit a text to the Google Cloud Natural Language Processing API (just set your own API keys). Google provides four different endpoints: analyzeEntities, analyzeSentiment, analyzeSyntax,and annotateText. After several trials, we realized that the annotated text method basically includes all the information returned by the other three single methods. For this reason, we suggest using this method for your initial experiments to get an overview of all the available analyses.
import httplib2
import sys
from googleapiclient import discovery
from googleapiclient.errors import HttpError
def test_language_api(content):
discovery_url = 'https://{api}.googleapis.com/$discovery/rest?version={apiVersion}'
service = discovery.build(
'language', 'v1',
http=httplib2.Http(),
discoveryServiceUrl=discovery_url,
developerKey=’__PUT_YOUR_KEY_HERE__’,
)
service_request = service.documents().annotateText(
body={
'document': {
'type': 'PLAIN_TEXT',
'content': content,
},
'features': {
'extract_syntax': True,
'extractEntities': True,
'extractDocumentSentiment': True,
},
'encodingType': 'UTF16' if sys.maxunicode == 65535 else 'UTF32',
})
try:
response = service_request.execute()
except HttpError as e:
response = {'error': e}
return response
The response of this natural language processing API is a JSON that contains:
- The language, which is automatically detected. Note that currently, sentiment detection only works with English (“en”), while also Spanish (“es”) and Japanese (“ja”) are supported for the entity analysis. This is athemain difference with the speech-to-text API, where the support for more than 80 different languages was a killer feature.
- The list of sentences. The content is split into sentences, using punctuation.
- The list of tokens. The content is split into tokens. Roughly speaking, a token usually corresponds to a word. Each token is enriched with syntactic information.
- The list of detected entities. Entities detected in the document are listed with their properties.
- The negative/positive polarity of the submitted content. We noticed that the API has changed over the past few days. While previous versions computed the polarity of the full submitted content, the latest version we experimented with offers a more granular analysis, returning the result for every single sentence.
Natural Language Processing API: Basics
The syntax analysis is based on linguistic concepts such as tokens, part of speech, a dependency tree, and entities. To better understand the output of the API, let’s take a closer look at each of these terms.
The token is the fundamental unit of textual analysis. It can be defined in various ways, but it often corresponds to 1 word = 1 token. The definition is not universal and it depends on the processing engine. For example, some engines treat “credit card” as a single token, while Google Natural Language Processing API splits it into two separate tokens (linked by a relationship). Each token has its own grammar type (e.g., noun, verb, adjective, etc.), usually denoted as Part of Speech (POS).
The POS is an important piece of information about the word itself and its role in the sentence, although it does not explicitly encode a relation with other tokens in the sentence. The NLP task that assigns each token with its appropriate POS is commonly called POS tagging.
One or more tokens can define an entity, i.e., either someone or something of interest mentioned in the text. In the case of proper nouns (e.g., Paris, New York, Madonna, Tom Cruise), the more specific term named entity is used. Typically, the Named Entity Recognition (NER) task detects proper nouns of People, Places, and Organizations in a given document. However, topic-specific entities such as dates, addresses, events, proteins, drug names, etc. can also be the target of entity extraction.
Finally, the structure encoding relations among words in the sentence is captured by a dependency tree. The tree includes syntactic/semantic relations such as:
- Verb-subject and verb-object
- John [subject] ← plays → [object] basketball
- Adjectival modifier for a given noun
- I see a yellow [adjectival modifier] ← ball
- Appositions
- Gandalf, the Wizard [apposition]
These relations constitute the “dependency edges” of the tree. The dependency concept encodes the word that each refers to. Let’s consider these two sentences:
- John watches a tree with a telescope
- John watches a tree with a nest
The tokens in the two sentences have the same grammar types, but their dependencies are different. In (1) “telescope” is linked via “with” to the verb “watches” (the telescope is what John uses to watch the tree) while in (2) “nest” is linked via “with” to “tree”, since the nest is an object placed on the tree and is not related to the “way John watches something”. Think of it this way: if you remove “tree” from (1), the telescope still has the “right” to be in the sentence, while this is not true for “nest” in (2).
Practical Demo with Natural Language
Let’s look at such definitions using the Google service. The sample text is extracted from ABC News and was passed to test_language_api() using the method defined above.
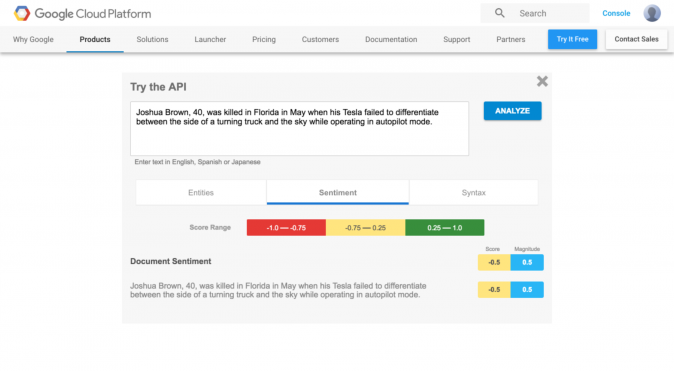
sample_content = """ Joshua Brown, 40, was killed in Florida in May when his Tesla failed to differentiate between the side of a turning truck and the sky while operating in autopilot mode. """ test_language_api(sample_content)
The result is in JSON:
'documentSentiment': {'magnitude': 0.5, 'polarity': -1, 'score': -0.5},
'entities': [{'mentions': [{
'text': {'beginOffset': 0, 'content': 'Joshua Brown'},
'type': 'PROPER'}],
'metadata': {},
'name': 'Joshua Brown',
'salience': 0.62338889,
'type': 'PERSON'},
...
]
'language': 'en',
'sentences': [{'sentiment': {'magnitude': 0.5, 'polarity': -1, 'score': -0.5},
'text': {'beginOffset': 0, 'content': '...'}}],
'tokens': [{'dependencyEdge': {'headTokenIndex': 1, 'label': 'NN'},
'lemma': 'Joshua',
'partOfSpeech': {'tag': 'NOUN', ...},
'text': {'beginOffset': 0, 'content': 'Joshua'}},
{'dependencyEdge': {'headTokenIndex': 6, 'label': 'NSUBJPASS'},
'lemma': 'Brown',
'partOfSpeech': {'tag': 'NOUN', ...},
'text': {'beginOffset': 7, 'content': 'Brown'}},
...
{'dependencyEdge': {'headTokenIndex': 6, 'label': 'P'},
'lemma': '.',
'partOfSpeech': {'tag': 'PUNCT', ...},
'text': {'beginOffset': 167, 'content': '.'}}
]
Our first impression was that the engine is robust in recognizing entities (note that “Joshua Brown” is listed among the entities as a person), directly linking them to the related Wikipedia page, when available. However, currently, the returned set of metadata is not particularly rich (and only the Wikipedia URLs are provided, if available). This is probably a work-in-progress feature. In addition, the engine computes the salience score, i.e., the importance of the entity in the sentence, even though it is not particularly accurate. In fact, in the example, it detected that Joshua Brown is relevant, but it scored “Tesla” and “autopilot mode” as less salient than Florida.
s for sentiment detection, it returned a negative polarity, as you can see in the returned field “documentSentiment”.
In accordance with the official documentation, the polarity is a value in the range [-1.0, 1.0], where larger numbers represent more positive sentiment. The magnitude is a non-negative number, which represents the absolute magnitude of sentiment regardless of polarity (positive or negative). In all of our experiments, the polarity assumed either the value 1 or -1, while magnitude was a positive, float number never greater than 1.0. From version v1, a third value is returned, “score”, that simply displays the product between the other two, in our case -0.5 (obtained multiplying 0.5 by -1.0).
How does the Natural Language Processing API handle edge cases?
We stressed the sentiment engine by applying small changes to the sample text, as follows.
First, we removed “killed”, a word with strong polarity. The system correctly recognized the sentence as negative, with a lower score.
sample_content = """
Joshua Brown, 40, was in Florida in May when his Tesla failed to differentiate
between the side of a turning truck and the sky while operating in autopilot mode."
"""
test_language_api(sample_content)
# output:
'documentSentiment': {
'magnitude': 0.2,
'polarity': -1,
'score': -0.2
},
In a second trial, we removed “failed to”, a verb with strong negative polarity. The meaning of the sentence has significantly changed compared to the original one, and the engine correctly detected the positive polarity of the new sentence.
sample_content = """
Joshua Brown, 40, was in Florida in May when his Tesla differentiate
between the side of a turning truck and the sky while operating in autopilot mode."
"""
test_language_api(sample_content)
# output:
'documentSentiment': {
'magnitude': 0.4,
'polarity': 1,
'score': 0.4
},
Finally, we removed other parts of the sentence, and the engine still correctly recognized a positive polarity.
sample_content = """
Joshua Brown was in Florida when his Tesla differentiate between
a turning truck and the sky.
"""
test_language_api(sample_content)
# output:
'documentSentiment': {
'magnitude': 0.5,
'polarity': 1,
'score': 0.5
},
To conclude, let us report a final example to test the disambiguation capabilities of the engine. Let’s consider the two sentences:
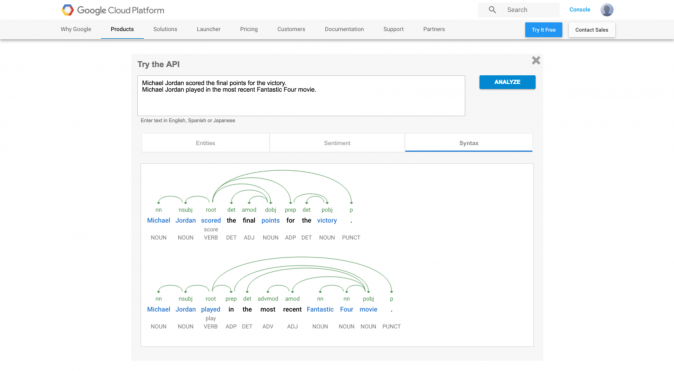
- Michael Jordan scored the final points for the victory.
- Michael Jordan played in the most recent Fantastic Four movie.
We can observe that the sentences refer to two different Michael Jordans. Surprisingly, the engine is also able to distinguish between the two different entities. In fact, in the first case, it returns the entity Michael Jordan, while in the second case it returns Michael B. Jordan. This means that, to some extent, the tool is able to disambiguate on the basis of some context around the entity. Digging a bit deeper, it looks like a strong clue, i.e., the “Fantastic Four” mention, is required for the correct disambiguation. In fact, if we remove the “Fantastic Four” mention from the second sentence and turn it into something like:
- Jordan played in a fantastic movie.
Michael Jordan is interpreted as the basketball player instead of the actor, despite the reference to “movie” and to the “cinema domain” in general. However, this isn’t an easy guess, and it’s not necessarily wrong: considering Michael Jordan’s role in Space Jam, we can turn a blind eye to this mistake 🙂
Conclusion
Our first impression of the Google Cloud Natural Language Processing APIs is a positive one. This is an easy-to-use tool for NLP basic features, and it can be easily integrated with any third party services and applications through the REST API. We are particularly impressed by the rich syntax (take a look at the large number of “Dependencies Labels“) and the accurate sentiment detection. The main issue is poor documentation. We hope that it will be enriched before a stable service is finally released. Also, the support for only a restricted set of languages is a strong limitation; we definitely expected wider support. One tip: Be careful when using the libraries as they are constantly being updated (also for versions no longer marked as Beta).
If we have aroused your curiosity, stay tuned over the next weeks for our new post, where we will discuss performance and further experiments on the Google Natural Language Processing APIs and other cloud services for NLP.