![]()
Cloud is all about elasticity. Cloud infrastructure running web-scale applications can shrink and grow dynamically. Batch processing on the cloud will have to deal with on-demand instantiation of the machines based on the load.
Google Compute Engine is a high performance, next-generation IaaS offering. One of the features that are still in preview-mode is called Replica Pools, which makes it easy to launch a fleet of virtual machines that share a common set of attributes. VMs that are never managed independently but run in a cluster or a group should be configured within a Replica Pool. For example, the pool can be a set of frontend web servers that have the same network and firewall configuration. Data nodes participating in Hadoop can be launched as a pool on GCE. You will never login to a specific machine running in these clusters to debug or configure since the configuration has to impact the whole set of machines.
What is a Replica Pool in Google Compute Engine?
Replica Pools feature makes it easy to create and manage homogeneous pools of VM instances called replicas. It is based on a common template that defines the configuration and attributes of the pool. A Replica Pool template defines attributes of an instance such as its base image, the details of any attached disks, attached networking objects and a startup script to be executed after the instance has booted. After you create a pool with a set of homogeneous replicas, you can use the Replica Pool API to resize, update, or delete the VMs from the pool. The Replica Pool service can also perform regular health checks on the VMs within a pool and can restart the VMs that fail to respond appropriately. This makes the pool self-healing by ensuring that it always has a pre-defined number of healthy VMs. The load balancer can be associated with a pool for evenly routing the traffic to all the machines.
Let’s understand the terminology of Replica Pools. It consists of two resources – 1) Replica and, 2) Pool. Replica represents a single virtual machine instance and the pool contains one or more replicas. Replicas are never launched directly. They are always managed through a pool.
The template that defines the Replica Pool is based on JSON. It contains the details including the initial size of the pool, the machine type, boot disk configuration, OS image followed by the network configuration. When you want to modify the pool, you change and apply the template to the pool.
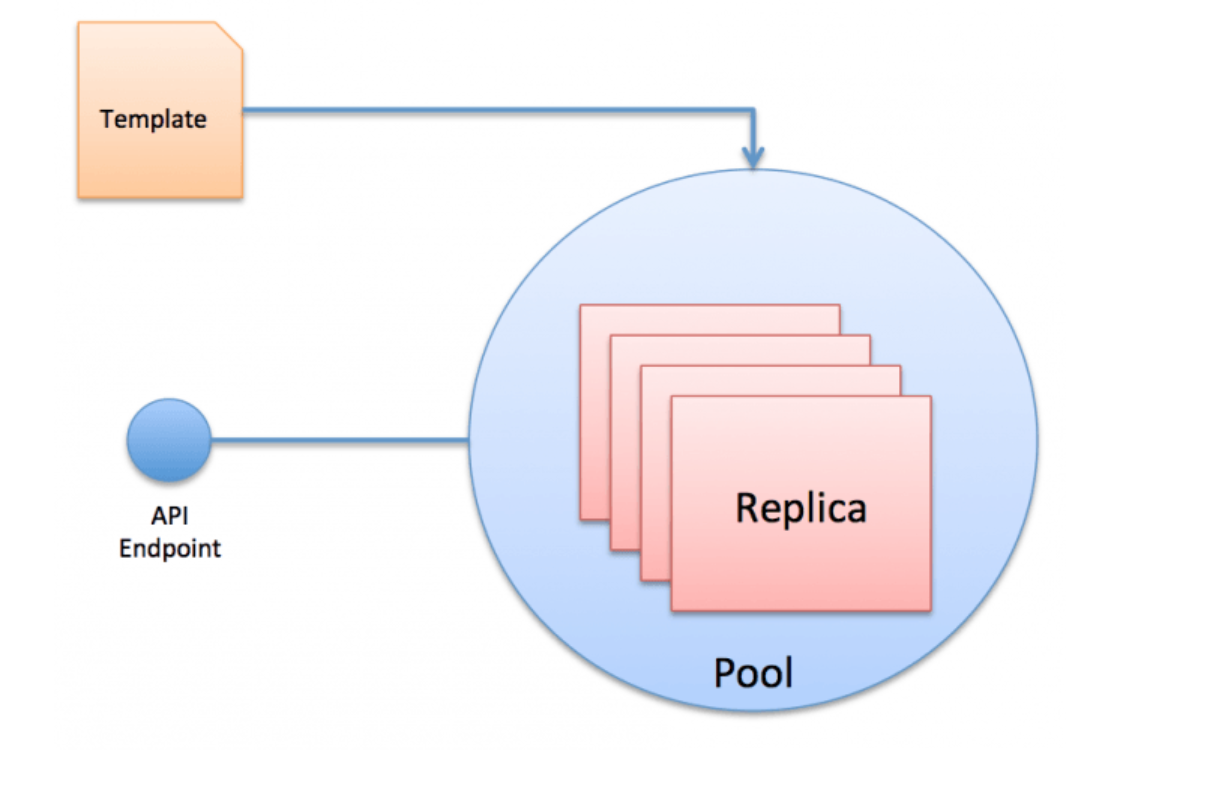
Like the other GCE resources, Replica Pool feature exposes REST API to manage the pool. You can query, resize, update the template and delete the pool by invoking the right API. You can also query the status and health of each replica (VM) in a pool through the API.
Since Replica Pool feature is in limited preview, you have to request access to get your account whitelisted. Please refer to the official documentation to gain access. We will explore the concept of Replica Pools further in this upcoming article: Understanding Google Cloud Deployment Manager.
How to learn Google Compute Engine with CloudAcademy.com
There’s a dedicated section for Google Compute Engine. We have a growing number of learning explanations and tests that you can use to quickly learn how to use GCE.