![]()
New AWS re:Invent Announcements: Swami Sivasubramanian Keynote

![]()
What an incredible week we’ve already had at re:Invent 2023! If you haven’t checked them out already, I encourage you to read our team’s blog posts covering Monday Night Live with Peter DeSantis and Tuesday’s keynote from Adam Selipsky.
Today we heard Dr. Swami Sivasubramanian’s keynote address at re:Invent 2023. Dr. Sivasubramanian is the Vice President of Data and AI at AWS. Now more than ever, with the recent proliferation of generative AI services and offerings, this space is ripe for innovation and new service releases. Let’s see what this year has in store!
Swami began his keynote by outlining how over 200 years of technological innovation and progress in the fields of mathematical computation, new architectures and algorithms, and new programming languages has led us to this current inflection point with generative AI. He challenged everyone to look at the opportunities that generative AI presents in terms of intelligence augmentation. By combining data with generative AI, together in a symbiotic relationship with human beings, we can accelerate new innovations and unleash our creativity.
Each of today’s announcements can be viewed through the lens of one or more of the core elements of this symbiotic relationship between data, generative AI, and humans. To that end, Swami provided a list of the following essentials for building a generative AI application:
In this post, I will be highlighting the main announcements from Swami’s keynote, including:
Let’s begin by discussing some of the new foundation models now available in Amazon Bedrock!

Just last week, Anthropic announced the release of its latest model, Claude 2.1. Today, this model is now available within Amazon Bedrock. It offers significant benefits over prior versions of Claude, including:
These enhancements help to enhance the reliability and trustworthiness of generative AI applications built on Bedrock. Swami also noted how having access to a variety of foundation models (FMs) is vital and that “no one model will rule them all.” To that end, Bedrock offers support for a broad range of FMs, including Meta’s Llama 2 70B, which was also announced today.
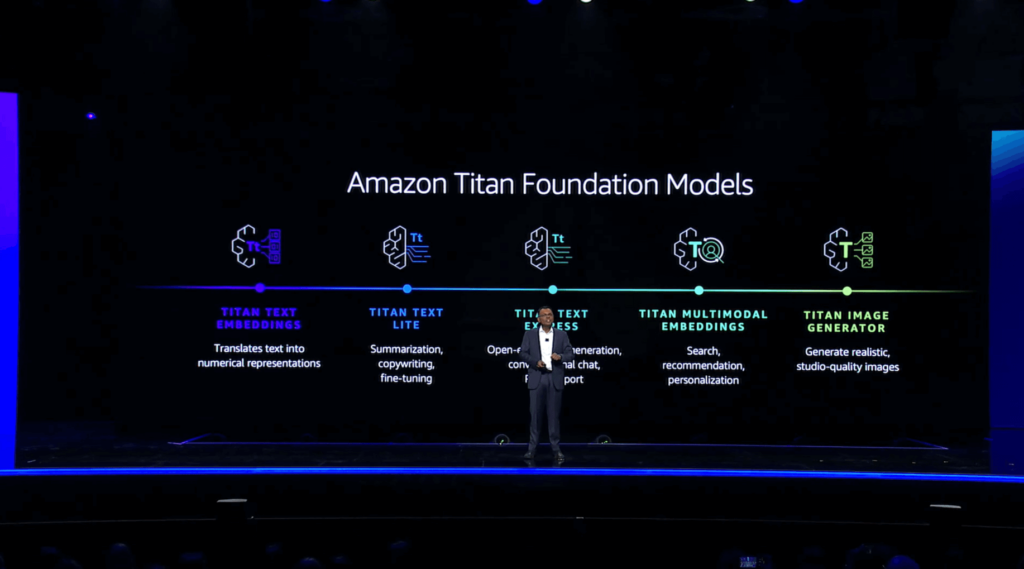
Swami introduced the concept of vector embeddings, which are numerical representations of text. These embeddings are critical when customizing and enhancing generative AI applications with things like multimodal search, which could involve a text-based query along with uploaded images, video, or audio. To that end, he introduced Amazon Titan Multimodal Embeddings, which can accept text, images, or a combination of both to provide search, recommendation, and personalization capabilities within generative AI applications. He then demonstrated an example application that leverages multimodal search to assist customers in finding the necessary tools and resources to complete a household remodeling project based on a user’s text input and image-based design choices.
He also announced the general availability of Amazon Titan Text Lite and Amazon Titan Text Express. Titan Text Lite is useful for performing tasks like summarizing text and copywriting, while Titan Text Express can be used for open-ended text generation and conversational chat. Titan Text Express also supports retrieval-augmented generation, or RAG, which is useful when training your own FMs based on your organization’s data.
He then introduced Titan Image Generator and showed how it can be used to both generate new images from scratch and edit existing images based on natural language prompts. Titan Image Generator also supports the responsible use of AI by embedding an invisible watermark within every image it generates indicating that the image was generated by AI.

Swami then moved on to a discussion about the complexities and challenges faced by organizations when training their own FMs. These include needing to break up large datasets into chunks that are then spread across nodes within a training cluster. It’s also necessary to implement checkpoints along the way to guard against data loss from a node failure, adding further delays to an already time and resource-intensive process. SageMaker HyperPod reduces the time required to train FMs by allowing you to split your training data and model across resilient nodes, allowing you to train FMs for months at a time while taking full advantage of your cluster’s compute and network infrastructure, reducing the time required to train models by up to 40%.

Returning to the subject of vectors, Swami explained the need for a strong data foundation that is comprehensive, integrated, and governed when building generative AI applications. In support of this effort, AWS has developed a set of services for your organization’s data foundation that includes investments in storing vectors and data together in an integrated fashion. This allows you to use familiar tools, avoid additional licensing and management requirements, provide a faster experience to end users, and reduce the need for data movement and synchronization. AWS is investing heavily in enabling vector search across all of its services. The first announcement related to this investment is the general availability of the vector engine for Amazon OpenSearch Serverless, which allows you to store and query embeddings directly alongside your business data, enabling more relevant similarity searches while also providing a 20x improvement in queries per second, all without needing to worry about maintaining a separate underlying vector database.

Vector search capabilities were also announced for Amazon DocumentDB (with MongoDB compatibility) and Amazon MemoryDB for Redis, joining their existing offering of vector search within DynamoDB. These vector search offerings all provide support for both high throughput and high recall, with millisecond response times even at concurrency rates of tens of thousands of queries per second. This level of performance is especially important within applications involving fraud detection or interactive chatbots, where any degree of delay may be costly.

Staying within the realm of AWS database services, the next announcement centered around Amazon Neptune, a graph database that allows you to represent relationships and connections between data entities. Today’s announcement of the general availability of Amazon Neptune Analytics makes it faster and easier for data scientists to quickly analyze large volumes of data stored within Neptune. Much like the other vector search capabilities mentioned above, Neptune Analytics enables faster vector searching by storing your graph and vector data together. This allows you to find and unlock insights within your graph data up to 80x faster than with existing AWS solutions by analyzing tens of billions of connections within seconds using built-in graph algorithms.

In addition to enabling vector search across AWS database services, Swami also outlined AWS’ commitment to a “zero-ETL” future, without the need for complicated and expensive extract, transform, and load, or ETL pipeline development. AWS has already announced a number of new zero-ETL integrations this week, including Amazon DynamoDB zero-ETL integration with Amazon OpenSearch Service and various zero-ETL integrations with Amazon Redshift. Today, Swami announced another new zero-ETL integration, this time between Amazon OpenSearch Service and Amazon S3. Now available in preview, this integration allows you to seamlessly search, analyze, and visualize your operational data stored in S3, such as VPC Flow Logs and Elastic Load Balancing logs, as well as S3-based data lakes. You’ll also be able to leverage OpenSearch’s out of the box dashboards and visualizations.

Swami went on to discuss AWS Clean Rooms, which were introduced earlier this year and allow AWS customers to securely collaborate with partners in “clean rooms” that do not require you to copy or share any of your underlying raw data. Today, AWS announced a preview release of AWS Clean Rooms ML, extending the clean rooms paradigm to include collaboration on machine learning models through the use of AWS-managed lookalike models. This allows you to train your own custom models and work with partners without needing to share any of your own raw data. AWS also plans to release a healthcare model for use within Clean Rooms ML within the next few months.

The next two announcements both involve Amazon Redshift, beginning with some AI-driven scaling and optimizations in Amazon Redshift Serverless. These enhancements include intelligent auto-scaling for dynamic workloads, which offers proactive scaling based on usage patterns that include the complexity and frequency of your queries along with the size of your data sets. This allows you to focus on deriving important insights from your data rather than worrying about performance tuning your data warehouse. You can set price-performance targets and take advantage of ML-driven tailored optimizations that can do everything from adjusting your compute to modifying the underlying schema of your database, allowing you to optimize for cost, performance, or a balance between the two based on your requirements.

The next Redshift announcement is definitely one of my favorites. Following yesterday’s announcements about Amazon Q, Amazon’s new generative AI-powered assistant that can be tailored to your specific business needs and data, today we learned about Amazon Q generative SQL in Amazon Redshift. Much like the “natural language to code” capabilities of Amazon Q that were unveiled yesterday with Amazon Q Code Transformation, Amazon Q generative SQL in Amazon Redshift allows you to write natural language queries against data that’s stored in Redshift. Amazon Q uses contextual information about your database, its schema, and any query history against your database to generate the necessary SQL queries based on your request. You can even configure Amazon Q to leverage the query history of other users within your AWS account when generating SQL. You can also ask questions of your data, such as “what was the top selling item in October” or “show me the 5 highest rated products in our catalog,” without needing to understand your underlying table structure, schema, or any complicated SQL syntax.

One additional Amazon Q-related announcement involved an upcoming data integration in AWS Glue. This promising feature will simplify the process of constructing custom ETL pipelines in scenarios where AWS does not yet offer a zero-ETL integration, leveraging agents for Amazon Bedrock to break down a natural language prompt into a series of tasks. For instance, you could ask Amazon Q to “write a Glue ETL job that reads data from S3, removes all null records, and loads the data into Redshift” and it will handle the rest for you automatically.

Swami’s final announcement circled back to the variety of foundation models that are available within Amazon Bedrock and his earlier assertion that “no one model will rule them all.” Because of this, model evaluations are an important tool that should be performed frequently by generative AI application developers. Today’s preview release of Model Evaluation on Amazon Bedrock allows you to evaluate, compare, and select the best FM for your use case. You can choose to use automatic evaluation based on metrics such as accuracy and toxicity, or human evaluation for things like style and appropriate “brand voice.” Once an evaluation job is complete, Model Evaluation will produce a model evaluation report that contains a summary of metrics detailing the model’s performance.

Swami concluded his keynote by addressing the human element of generative AI and reaffirming his belief that generative AI applications will accelerate human productivity. After all, it is humans who must provide the essential inputs necessary for generative AI applications to be useful and relevant. The symbiotic relationship between data, generative AI, and humans creates longevity, with collaboration strengthening each element over time. He concluded by asserting that humans can leverage data and generative AI to “create a flywheel of success.” With the impending generative AI revolution, human soft skills such as creativity, ethics, and adaptability will be more important than ever. According to a World Economic Forum survey, nearly 75% of companies will adopt generative AI by the year 2027. While generative AI may eliminate the need for some roles, countless new roles and opportunities will no doubt emerge in the years to come.

I entered today’s keynote full of excitement and anticipation, and as usual, Swami did not disappoint. I’ve been thoroughly impressed by the breadth and depth of announcements and new feature releases already this week, and it’s only Wednesday! Keep an eye on our blog for more exciting keynote announcements from re:Invent 2023!