![]()
This is a guest post from 47Line Technologies.
In Data Versioning with DynamoDB – An inside look into NoSQL, Part 5, we spoke about data versioning, the 2 reconciliation strategies and how vector clocks are used for the same. In this article, we will talk about Handling Failures.
Handling Failures – Hinted Handoff
Even under the simplest of failure conditions, DynamoDB would experience reduced durability and availability if the traditional form of quorum approach is used. In order to overcome this it uses a sloppy quorum; all READ and WRITE operations are performed on the first N healthy nodes from the preference list, which may not be the first N nodes encountered by traversing the consistent hashing ring.
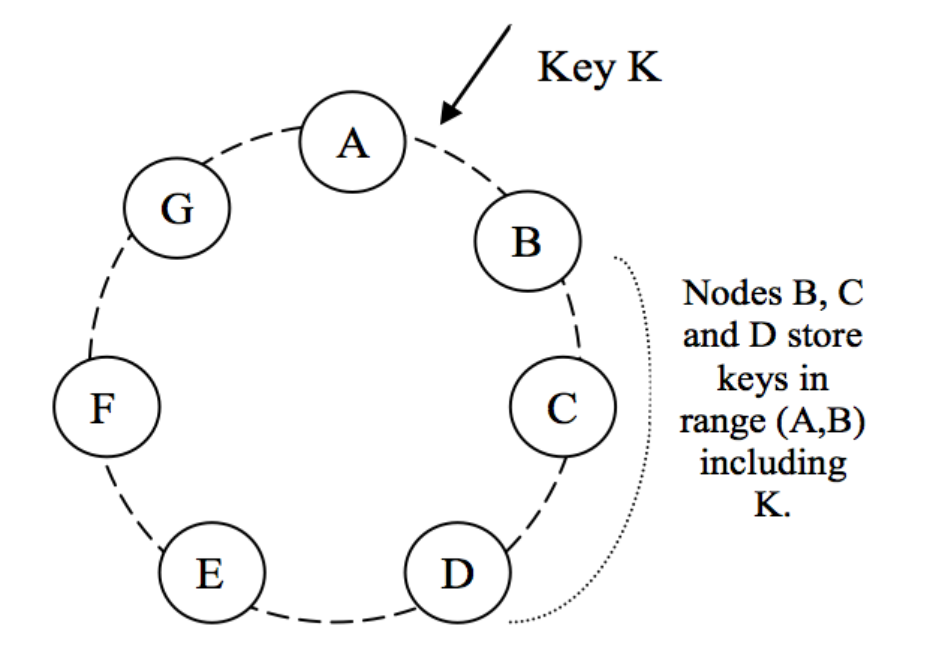
Partitioning & Replication of Keys in Dynamo ()
{kind=link}
Consider the above figure: If A is temporarily not reachable during a WRITE operation, then the replica that would have lived on A will be sent to D to maintain the desired availability and durability guarantees. The replica sent to D will have a hint in its metadata which tells who the intended recipient was (in our case, it is A).
The hinted replicas are stored in a separate local database which is scanned periodically to detect if A has recovered. Upon detection, D will send the replica to A and may delete the object from its local store without decreasing the total number of replicas. Using hinted handoff, DynamoDB ensures that READ and WRITE are successful even during temporary node or network failures.
Highly available storage systems must handle failures of an entire data center. DynamoDB is configured such that each object is replicated across data centers. In terms of the implementation detail, the preference list of a key is constructed such that the storage nodes are spread across multiple data centers and these centers are connected via high-speed network links.
Handling Permanent Failures – Replica Synchronization
Hinted Handoff is used to handle transient failures. What if the hinted replica itself becomes unavailable? To handle such situations, DynamoDB implements an anti-entropy protocol to keep the replicas synchronized. A Merkle Tree is used for the purpose of inconsistency detection and minimizing the amount of data transferred.
According to Wikipedia, a “Merkle tree is a tree in which every non-leaf node is labeled with the hash of the labels of its children nodes.”. Parent nodes higher in the tree are hashes of their respective children.
The principal advantage of a Merkle tree is that each branch of the tree can be checked independently without requiring nodes to download the entire tree or the entire data set. Moreover, Merkle trees help in reducing the amount of data that needs to be transferred while checking for inconsistencies among replicas. For instance, if the hash values of the root of two trees are equal, then the values of the leaf nodes in the tree are equal and the nodes require no synchronization. If not, it implies that the values of some replicas are different. In such cases, the nodes may exchange the hash values of children and the process continues until it reaches the leaves of the trees, at which point the hosts can identify the keys that are “out of sync”.
DynamoDB uses Merkle trees for anti-entropy as follows: Each node maintains a separate Merkle tree for each key range (the set of keys covered by a virtual node) it hosts. This allows nodes to compare whether the keys within a key range are up-to-date. In this scheme, two nodes exchange the root of the Merkle tree corresponding to the key ranges that they host in common. Subsequently, using the tree traversal scheme described above the nodes determine if they have any differences and perform the appropriate synchronization action. The disadvantage with this scheme is that many key ranges change when a node joins or leaves the system thereby requiring the tree(s) to be recalculated.
In the next and the final part of this series, we will discuss Membership and Failure Detection.