![]()
New expanded content showing all three AWS Serverless posts in one article. This is a detailed look at the components of AWS Serverless Architecture and how anyone can make the most of it. Because of the complexity of the subject, this post has been subdivided into 3 sections, each with a conclusion.
The advantages of serverless architecture are game-changing.
What does a typical 3-tier architecture look like? In a very generic deployment, there are three building blocks for a 3-tier architecture: a presentation layer, business logic layer, and database layer.
An amazing array of applications and frameworks have been designed, developed, and sometimes thrust upon us to adhere to this basic principle of web-application design. To make things more complicated, we have to take care of auto-scaling, caching, routing and many other tasks that add up to an organizations’ responsibilities. Recently, a new way of using serverless architecture has emerged, and Amazon Web Services (AWS) is taking all right steps to make serverless architecture friendlier and more powerful.
Why serverless architecture?
Servers or, EC2 instances, are powering thousands of popular sites and application. But to do that, servers cost money and a minimum number of servers are required to run the websites. Those servers need permanent disks, caching layers, and more scaffolding services to serve user requests. Servers require frequent refreshing with hardware and software to keep them up-to-date and bug-free. Serverless architecture, or services, play a significant role to address these issues, including managing costs, and performance. This is not to say that there will be no servers involved. Users, developers, and organizations building their applications with popular frameworks can now focus on their applications, not their backend.
Advantages serverless architecture offers:
- No OS, no licensing cost, and nothing to manage (a good thing).
- No minimum or over-provisioning costs.
- No hardware or software refreshing or patching concerns.
How will we achieve these goals? Well, in this series of posts, we are going to discuss some of the Amazon’s game-changing technologies that are making serverless architecture a reality.
We are going to discuss following AWS services in a general way, offering an overview of the technologies. We will discuss sample applications developed by these technologies and the use-cases for these implementations. I think it is worthwhile reviewing the AWS documentation and blog posts, then do some hands-on exercises. The services that are considered for serverless architectures are:
Services for serverless architectures are:
The last two services are well known. They don’t make a great platform for production grade infrastructure entirely, but I have implemented S3 static website hosting for a number of very large organizations, and they are static running at their best, even after a couple of years.
Let’s discuss the Amazon API Gateway. We will cover a few basic building blocks and the AmazonAPI Gateway’s space and capability for a serverless architecture.
Amazon API Gateway:
The Amazon API Gateway is part of Amazon’s serverless-architecture logic tier. According to Amazon’s documentation:
“Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. With a few clicks in the AWS Management Console, you can create an API that acts as a “front door” for applications to access data, business logic, or functionality from your back-end services, such as workloads running on Amazon Elastic Compute Cloud (Amazon EC2), code running on AWS Lambda, or any Web application. Amazon API Gateway handles all the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls, including traffic management, authorization and access control, monitoring, and API version management.”
This means that the Amazon API Gateway provides users a means to use HTTP(S) requests for other Amazon serverless infrastructures, such as Lambda functions, or a data tier from the presentation layer, such as websites or mobile applications. This is the entry point for users to the Amazon serverless logic tier. Behind the scenes, the API Gateway uses Amazon CloudFront to distribute the load globally.
Amazon API Gateway is based on two services:
- API Gateway Control Service – which lets developers create REST-ful APIs to consume bank-end services, like Amazon Lambda, DynamoDB, or an existing website. The created API consists of resources and methods.
- A resource is a logical entity that can be accessed through a resource path using the API. A resource responds to any of the REST-ful operations, such as GET, POST, and DELETE. A combination of a resource path and an operation identify a method in the API. The API Gateway integrates the method with a targeted back end by mapping the method request to an integration request acceptable by the back end. And then mapping the integration response from the back end to the method response returned to the user.
- API Gateway Execution Service – lets the app call the backend services exposed by Control Service.
There are 3 different roles for API Gateway users:
- API Developer or API Owner – User with the AWS Account who owns API deployment.
- App Developer or Client Developer – Who interacts with the deployed API. The App Developer can be represented by API key.
- App users, end users, or client endpoint – An entity that uses the application, built by an app developer that interacts with APIs in Amazon API Gateway. An app user can be represented by an Amazon Cognito identity or a bearer token.
Creating an API:
- Create or update an IAM user with APIGateway AccessPolicy such as “AmazonAPIGatewayAdministrator”.
- This user should be able to use the API Gateway services. It is better to create or update a non-root user for API Gateway service.
- Go to the “Amazon API Gateway” service. Click on Get Started if you are the first time user. The below screen will appear. Give an API name and an optional description and click on “Create API”.

- Create a child resource from selecting “Create Resource” from the Actions. The resulted resource will be the child of the resource root. To create a grandchild resource, select the newly created resource and create another resource. The action will create a resource with a name starting with / and the given name by the user. The resource path will be automatically populated. Here is the screenshot.

- Now create one or more method for the resource. Choose the resource you want to create a method for and click “Create Method” from Actions.
- From the drop-down select an HTTP verb for method e.g. GET, POST, DELETE etc.

- The next page will show the integration with the back end.
- There are options for Integration Type with Lambda Function, HTTP Proxy or Mock Integration. We will select Mock Integration for simplicity in this post, but we will stop here for other integration because we need to get an understanding of the AWS Lambda. We will also configure a Lambda function to associate with Amazon API Gateway resource and method in following posts.
- After choosing “Mock Integration”, we are shown the following dashboard:

- The dashboard has many terms that we should familiarize ourselves with to better understanding the method in the API Gateway:
- Method request – The public interface of an API method in the API Gateway that defines the parameters and body which an app developer must send requests to access the back-end through the API.
- Integration request – An API Gateway internal interface that defines how API Gateways maps the parameters and body of a method request into the formats required by the back end.
- Integration response – An API Gateway internal interface that defines how API Gateway maps data. The integration response includes the status codes, headers, and payload that are received from the back end into the formats defined for an app developer.
- Method response – The public interface of an API that defines the status codes, headers, and body models that an app developer should expect from API Gateway.
- Coming back to our example, Select Body Mapping Template and select application/json. Edit the mapping template with some sample template. I have used something like this:

- The next configurations are as follows. In the Method Request, enter a URL query string parameter “cloudService”:

- The next configuration will be, Method Response. Provide all the response code that you want to see. In our Integration Request, we have provided 200, 400 & 500 for the response code. Those need to be configured/added here by clicking on “Add Response Header”.

- In Integration Response, we have to provide the response we are expecting in case the of an HTTP code generation. Here are the configuration screenshot for 200, 400 & 500 HTTP codes. Note that, the response template will be configured in Body Mapping Templates.



- The next step is testing.
- Go back to the Method Execution dashboard and click test.
- Provide AWS in the queryString box and click on test. The output will be the desired 200 OK HTTP message and the integration response will be :

- The 400 or 500 HTTP messages are as follows:


Conclusion:
We just finished our first Amazon API Gateway hands-on project. This is only a mock execution, but it opens the possibilities for building a real, scalable backend service, and fronting it with both mobile clients and websites.
All of this may be accomplished without servers or other infrastructure in any part of the system: front-end, back-end, API, deployment, or testing. As I said in the introduction, we are only scratching the surface here and the best is yet to come. Cloud Academy offers a free 7-day trial that allows users access to development environments through hands-on labs, quizzes, courses, and curated learning paths. For additional reading, I suggest a post from October by Alex Casalboni, AWS Lambda and the Serverless Cloud.
AWS Lambda is a good friend to Cloud professionals.
In a typical 3-tier application you need numerous code modules to perform tasks that are application critical and enhance the application’s feature. To put the code into work, you need the infrastructure to run. For example: To transcode an image that you put in your AWS S3 bucket you need some coding, an infrastructure to run the code, and the skill to install & run the infrastructure.
Quite a task. As a programmer, you are not expected to think about the other two skills — installing and managing infrastructure. If you are using AWS cloud, you set must set up an EC2 server, apply a run-time environment, like Java SDK, app server etc. These are the bare minimum requirements and they are complicated. Is there a better way?
AWS believes there should be and introduced a service called AWS Lambda as part of their serverless architecture. Lambda, in simple terms, is a service that reduces the effort of running application code in response to some events, and automatically provisions resource for you.
Consider our problem of transcoding the image that we need to put in our S3 bucket. We have a sample app that only allows the image to be .jpeg format and must be less than 200 KB. To run this code, we need an EC2 server and a Tomcat web server to run the java code for the task.
Thankfully, we can now do the same thing with Lambda, and with much less effort. With lambda, you upload your application code zip file — or even write your code in the inline editor provided by AWS Lambda console, and get going.
According to AWS Lambda documentation: “AWS Lambda runs your code on high-availability compute infrastructure and performs all the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code and security patch deployment, and code monitoring and logging. All you need to do is supply your code in one of the languages that AWS Lambda supports (currently Python 2.7, Node.js (0.10 or 4.3) Java 8 or higher).”
That’s a lot of behind the scenes work, and that’s the beauty of working with Lambda, automation.
Why you should choose AWS Lambda:
AWS Lambda is a serverless compute platform for executing Stateless and event-driven code execution. What does this mean for a user, programmer, or AWS administrator. It means that AWS runs a chunk of optimized java script functions, or Lambda functions that carry out an event driven task. An event-driven task can be an object added/deleted in S3 bucket, a table updated in DynamoDB, a message arriving to an AWS Kinesis stream or SQS, when a lifecycle event occurs in AWS EC2, or any custom event in AWS.
Best uses for AWS Lambda:
AWS Lambda use-cases can be categorized into four broad sections:
- AWS Lambda with AWS Services as Event Source: As mentioned earlier, various AWS services can be used as an event source for AWS Lambda. The event sources can be Amazon S3, Kinesis, DynamoDB (we already have a blog post on AWS & DynamoDB), CloudTrail, SNS, SES and a lot more. We will see how we can use S3 as an event source in our next practical hands-on example.
- On-demand Lambda function invocation over HTTPS (Amazon API Gateway): In a previous blog post, we described using the Amazon API Gateway. We can call an AWS Lambda function using REST API over HTTP(S). We will see the complete example of a serverless architecture using both Amazon API Gateway and AWS Lambda later.
- Using custom Apps: Any application such as web or mobile apps can invoke AWS Lambda using AWS SDK or AWS Mobile SDK. Example to come.
- Scheduled Event: Set up AWS Lambda as a scheduler to run user code at specified interval of time (like a cron job).
Working in AWS Lambda Console:
Pre-requisites:
Following pre-requisites are required for Amazon Lambda execution:
- Amazon Lambda access
- Knowledge of Python, java (1.8 or above) and Node.js as programming languages
- Supported libraries for executing the code
Currently, Lambda is supported in the US-east (N. Virginia), US-west (Oregon), EU (Ireland), EU (Frankfurt) & Asia-pacific (Tokyo) regions.
When you start using Lambda, you already have some sample functions ready for use. Take a look:

I have chosen the “hello-world” application. In future, we are going to execute more complex, real-world examples. Keeping things simple at the start is often the best way of building skills and confidence. I suggest we use this example for familiarization with Lambda.
Take a look at the next screen:

Name: Name of your Lambda function. E.e. HW_lambda
Description: A short description of what the function does for reference
Runtime: You can choose Python 2.7, Node.js 0.10 or 4.3 or Java 8.
Lambda function code:

The next section is code-entry type. You can upload your .zip file or even write the code in-line. Let choose in-line for this example. In the in-line code snippet, we have added a console.log that says, “Hello world Lambda.” Notice the syntax check against our code. It suggests we missed a semicolon (;). Fantastic, isn’t it?
Lambda function handler and role:
Handler: When you create a Lambda function you must specify the handler in your code that will receive the events and process them. In the console, you specify the handler in the Handler box. A handler function has the following signature:
outputType handler_name(inputType input, Context context) {
…..
}
In order for a Lambda function to successfully invoke a handler, it must be invoked with input data that can be serialized into the data type of the input parameter.
If you plan to invoke the Lambda function synchronously, you can mention output_type. For an asynchronous Lambda function invocation (using Event invocation type), the output type should be void.
Role: This role is mapped to AWS IAM role. This role should have sufficient permission to perform AWS actions that the lambda function needs. Let’s choose Basic Execution Role from “create role.”

We kept the default values, and “Allow.” You then set Memory and Timeout values. Click “Next” and “Create function.” After the function is created, execute it with the “Test” button.

Now, I offer a more practical example.
We want to send welcome emails to users who have registered with our portal. I have a runnable jar file which is 29MB with all dependent jar files from aws-sdk and java.mail.
- The path of the jar will go in S3 link URL. I have my file at /bbq-bucket/source/s3update.jar. The S3 bucket and S3 key will be auto-populated after the S3 link URL entry.
- The handler entry should be <package-name>.<class-name>::<method-name>. In this case, we have AWSS3Client::createNewFile.

- Click “Next” and “Create Function.” Once the function is created, you should test it.

- Then check the output.
- Once successfully implemented, you can check the output and the inbox of recipient mail.
This ends our hands-on example of sending welcome emails when a file is uploaded in an S3 bucket.
Conclusion:
Lambda is a really cool offering from Amazon Web Service. It is actually a microservice from AWS to run the application code from different sources. It is iterating, maturing, and evolving all the time. Try out lambda and see what you can do with it. Maybe share your results with us here or on other public platforms.
Amazon API Gateway and AWS Lambda are my pics for foundation architecture for Amazon serverless architecture. Cloud Academy offers a free 7-day trial subscription where you may work in a real AWS environment without signing up for one. They provide hands-on labs, learning paths, and quizzes that support the video learning courses.
AWS Lambda is massively useful and can be configured with almost all important AWS services.
I have written widely about Amazon Kinesis because it offers managed real-time event processing, and I love it. This is an exceptionally useful and intuitive service. I’ve described Amazon Kinesis in-depth in a previous post from 2015 so if you have questions about that service check the link above,
Below, I’ll show you how AWS Lambda and Amazon Kinesis integration works.
Push Event Model and Pull Event Model:
To learn about this integration, we are going to discuss two very important event models of the AWS Lambda functionality concept: Push Event Model vs Pull Event Model.
- How does the Lambda function get invoked?
- When an event occurs, what detects the event and invokes a Lambda function?
- If an object is added to an Amazon S3 bucket or a record is added to a DynamoDB stream, is it the event source or AWS Lambda that detects the events and invokes your Lambda function?
Understanding of the nitty-gritty of AWS services will take you to a long way designing applications using Lambda.
Some event sources publish events, but AWS Lambda must poll the event source and invoke your Lambda function when events occur. This is called the pull model. With appropriate permissions, AWS Lambda maintains an event source mapping from where it will pull the events. AWS Lambda provides APIs for users to write the code for source mapping. When an event occurs at the designated source a record is added to the Kinesis stream. This is treated as an event and the Lambda function is invoked. This is an example of AWS Lambda function Pull Event Model, where AWS Lambda polls the event to invoke your Lambda function.
Some of the event sources can publish events to AWS Lambda and directly invoke your Lambda function. This is called the push model where the event sources invoke your Lambda function. In this model, you maintain association of a Lambda function with its event source, and not in AWS Lambda. For an example, when you add an object to an S3 bucket, S3 detects it as an event and calls a Lambda function to execute for some action, say, to compress it. In this case, AWS Lambda does not maintain the event source mapping, but the service or application calls the Lambda service to take some action.
Coming back to our example of AWS Lambda and Kinesis integration, we found that it will be a pull model. When a record is added to the Kinesis stream whose event source mapping will be created and maintained by the developer using APIs, AWS Lambda will invoke the associated Lambda function to execute the designated action. There are two ways you can create event source mapping, either by using
There are multiple ways of creating event source mapping. You can use the CreateEventSourceMapping API, or the Lambda console. But the pulling model is not the only option for AWS Lambda and Kinesis integration. There is a synchronous invocation using RequestResponse invocation type. The third option is to configure event source mapping by creating a batch of records per invocation of the Lambda function. Users must note that, for the integration of AWS Lambda and Amazon Kinesis, both the services should reside in the same region.
Example of AWS Lambda and Kinesis:
To execute the example, we assume that you have an AWS account with administrator permission and you have AWS CLI installed on your workstation. Also get the following jars through maven or download them from github/maven repo.
- aws-lambda-java-core – github, maven repository
- aws-lambda-java-events – github, maven repository
Add these libs to your build path and start a new eclipse project. In this example, we have created a Java class “ProcessKinesisEvents” and the handler method is “recordProcessor()”. We are trying to read a batch of records and process them. If the handler processes them successfully, then the next batch will be read and processed, otherwise, Lambda will retry the batch.
The code snippet is as follows:
package example;
import java.io.IOException;
import com.amazonaws.services.lambda.runtime.events.KinesisEvent;
import com.amazonaws.services.lambda.runtime.events.KinesisEvent.KinesisEventRecord;
public class ProcessKinesisEvents {
public void recordProcessor(KinesisEvent event) throws IOException {
for(KinesisEventRecord rec : event.getRecords()) {
System.out.println(new String(rec.getKinesis().getData().array()));
}
}
}
The following artifacts have been created to execute this example.
- The function name is “JavaKinesisExample.” It will run in a java 8 environment.
- The zip we have created from the Project is named “lambda-kinessis-processor.jar.”
- The handle name should be “example.ProcessKinesisEvents::recordProcessor.”
- The AWS Role that we have created in IAM is AWSLambdaRole with the Policy “AWSLambdaKinesisExecutionRole” attached to it.
- Keep the memory as 512 MB.
- Set the timeout to 30 seconds and select “No VPC”.

- Click “next” and “Create Function.”

- Click Save and Test.
- Click on Test and in the “Input Test Events,” enter the Sample event template as “Kinesis” and click “Save and Test.”

- The following output will appear from the kinesis test stream.
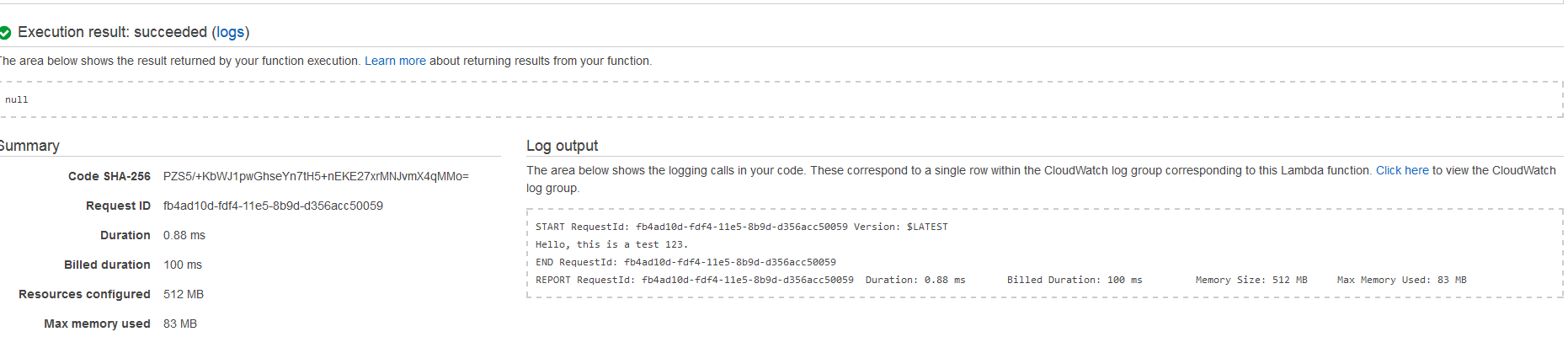
- The output is “Hello, this is a test 123.”
- This is an example Kinesis stream data. You can check the logs in CloudWatch by clicking the “Click here” button in the Log output section.
- The resulting page will be:

- Click on the log stream and you can see the event data.

The above example is one of the simplest I could find and is intended for illustrating manually handling streaming data from a Kinesis stream. For a full-fledged Kinesis stream application, you should have strong, working understanding of Amazon Kinesis — which I highly recommended if you have the time.
AWS Lambda monitors Lambda functions automatically in CloudWatch. If you have navigated to the Logs link above, you should notice the Metrics, Lambda, and Logs options with which to monitor the Lambda function life cycle.
Lambda automatically tracks the number of requests, the latency per request, and the number of requests resulting in an error. It then publishes the associated CloudWatch metrics and generates customized alarms. Users can create dashboards of executed Lambda functions with ease.
Before moving ahead with real-world Lambda or other services that facilitate Amazon’s server-less architecture, it is a good idea to review the best practices and limitations of the AWS Lambda.
I have done my best in listing them carefully below.
AWS Lambda Best Practices:
If you are familiar with 12-factor apps, then following the recommended best practices for using AWS Lambda will fall in the same category.
Some of the best practices from AWS Lambda developer guides are:
- Lambda function code in a stateless style, and ensure there is no affinity between your code and the underlying compute infrastructure.
- Avoid declaring any function variables outside the scope of the handler. Lambda does not guarantee those variables will be refreshed between function invocations.
- Make sure you have set read, execute permissions on your files in the uploaded ZIP/jar to ensure Lambda can execute code on your behalf.
- Lower costs and improve performance by minimizing the use of startup code not directly related to processing the current event.
- Use the built-in CloudWatch monitoring of your Lambda functions to view and optimize request latencies.
- Delete old Lambda functions that you are no longer using.
AWS Lambda Limitations:
AWS Lambda has the following limitations:
- Default limit ephemeral disk capacity (“/tmp” space) is 512 MB
- Default limit for number of file descriptors is 1,024
- Default limit for number of processes and threads (combined total) 1,024
- Maximum execution duration per request 300 seconds
- Lambda function deployment package (zip/jar) size cannot exceed 50 MB
- Size of code/dependencies that you can zip into a deployment 250 MB
- Concurrent executions can be a maximum of 100.
Conclusion:
Our journey to achieve Amazon server-less architecture is taking shape but is in the early stages yet. We are constantly adding posts to make the readers comfortable with the pace. However, adoptions of Amazon server-less services are blazing fast, and everybody who loves AWS services is trying their hand with them. Cloud Academy offers a free 7-day trial subscription that allows you access to their many learning resources. I suggest you check out a video course Understanding AWS Lambda and a hands-on lab Introduction to AWS Lambda.