![]()
 In the first article about Amazon EMR, in our two-part series, we learned to install Apache Spark and Apache Zeppelin on Amazon EMR. We also learned ways of using different interactive shells for Scala, Python, and R, to program for Spark.
In the first article about Amazon EMR, in our two-part series, we learned to install Apache Spark and Apache Zeppelin on Amazon EMR. We also learned ways of using different interactive shells for Scala, Python, and R, to program for Spark.
 In the
In the Let’s continue with the final part of this series. We’ll learn to perform simple data analysis using Scala with Zeppelin.
Access the Zeppelin Notebook
Before we can access the Zeppelin Notebook, we need to forward all requests from localhost:8890 to the master node. This is because port 8890 is bound on the master node, and not on our local machine.
$ ssh -i cloudacademy-keypair.pem -L 8890:ec2-[redacted].compute-1.amazonaws.com:8890 hadoop@ec2-[redacted].compute-1.amazonaws.com -Nv [...] Authenticated to ec2-[redacted].compute-1.amazonaws.com ([redacted]:22). debug1: Local connections to LOCALHOST:8890 forwarded to remote address ec2-[redacted].compute-1.amazonaws.com:8890 debug1: Local forwarding listening on ::1 port 8890. debug1: channel 0: new [port listener] debug1: Local forwarding listening on 127.0.0.1 port 8890.
Having done that, we can now access http://localhost:8890/.

Analyze the data!
Zeppelin has a clean and intuitive web interface that does not need much explanation to get started. We can start by creating a new note.
We will use a dataset that is hosted on Amazon S3 as an example. The URL to the S3 public bucket is s3://us-east-1.elasticmapreduce.samples/flightdata/input/. This dataset is fairly large. It is around 4GB when it is compressed, and 79GB after uncompression. It is pulled from Amazon’s official blog post, New – Apache Spark on Amazon EMR. The dataset originally came from the US’s Department of Transportation and is a good size to play with.
To add text in the notebook, we begin the text with %md.

We will read the dataset from a public, read-only S3 bucket to a DataFrame. There are a total of 162,212,419 rows.

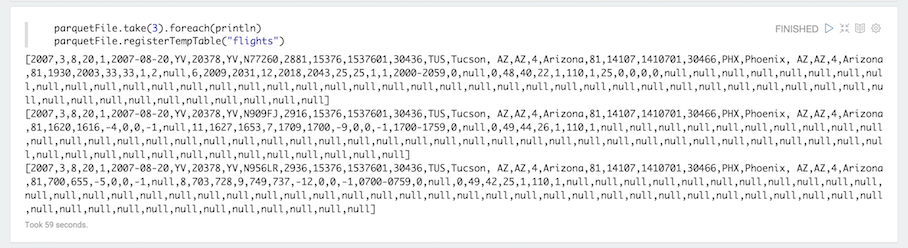
We will display the first three records of the dataset. While we are at it, let’s also register the DataFrame as a table so that we can query them with SQL statements.
We can query for the top 10 airports with the most departures since 2000. The top three airports are Hartsfield–Jackson Atlanta International Airport (ATL), O’Hare International Airport (ORD), and Dallas/Fort Worth International Airport (DFW). Is anyone surprised by these three? I was a little.

Next, we will query for the top 10 airports with the most flight delays over 15 minutes since 2000, and the top three are: O’Hare International Airport (ORD), Hartsfield–Jackson Atlanta International Airport (ATL), and Dallas/Fort Worth International Airport (DFW).

How about we look at flight delays over 60 minutes instead? We see the same top three airports in the same order again.

Let’s look at the top 10 airports with the most flight cancellations. Again, the same top three airports are O’Hare International Airport (ORD), Dallas/Fort Worth International Airport (DFW), and Hartsfield–Jackson Atlanta International Airport (ATL). Maybe it is wise to avoid these airports if we can!

And finally, the top 10 most popular flight routes. The top three routes were Los Angeles International Airport (LAX) to McCarran International Airport (LAS), Los Angeles International Airport (LAX) to San Francisco International Airport (SFO), and Los Angeles International Airport (LAX) to San Diego International Airport (SAN).

Terminating the EMR cluster
Always remember to terminate your EMR cluster after you have completed your work. As we are running a cluster of machines, we will be billed for using the EMR box per hour as well as the on-demand Linux instances per hour. These charges can add up very quickly especially if you run a large cluster. So to avoid spending more than you should, do terminate your EMR cluster if you do not need to use it.
$ aws emr terminate-clusters --cluster-id j-ABCDEFGHIJKLM
$ aws emr describe-cluster --cluster-id j-ABCDEFGHIJKLM | grep State\"\:
"State": "TERMINATING",
"State": "TERMINATING",
"State": "TERMINATING",
What’s next?
In this article, we have learned to read in a large dataset from an S3 public bucket. We have also performed SQL queries on the dataset to answer a few interesting questions (if you live in the US, or have to travel to the US frequently). If you have followed along the examples here, you will soon realize that there is a limitation to this setup. The changes we have made on Zeppelin is only persistent as long as the EMR cluster is running. If we were to terminate EMR, we will also lose the changes on Zeppelin. Zeppelin itself does not support exporting or saving of its notebooks (yet, I hope). Obviously, this is not ideal. If you have a suggestion on how we can avoid this problem, I would love to hear from you.
We are only scratching the surface on this topic. I hope it gives you a good starting point to learn more about Amazon EMR. If you are interested to learn more about the other supported projects in EMR, give me your suggestions on what you would like to read in my future blog posts. I am more than happy to learn and share my knowledge with you.