![]()
Want to learn more about using Apache Spark and Zeppelin on Dataproc via the Google Cloud Platform? You’ve come to the right place.
Cloud Dataproc is Google’s answer to Amazon EMR (Elastic MapReduce). Like EMR, Cloud Dataproc provisions and manage Compute Engine-based Apache Hadoop and Spark data processing clusters.
If you are not familiar with Amazon EMR, check out my two-part series about using Apache Spark and Zeppelin on EMR – See Part 1 and Part 2. You may find my notes on IAM helpful, too.
First Impressions: The Key Differences between EMR and Cloud Dataproc
Cloud Dataproc is fairly new. It was first released in beta last September, and is now generally available since February this year. If you have previously used EMR, you may find Cloud Dataproc familiar.
An important difference I have observed is this: In EMR, when you create a cluster, you know exactly what you are installing because you are presented with an option to choose from a list of supported Hadoop components. Cloud Dataproc, on the other hand, will just install all the supported components by default.
EMR is a more mature platform. After all, it has been around since 2009. It has support for many applications, including Tez, Ganglia, Presto, HBase, Pig, Hive, Mahout, Sqoop, and Zeppelin. As for Cloud Dataproc, it only supports Hadoop, Spark, Hive, and Pig (see the supported Cloud Dataproc versions page). Fortunately, you can specify initialization actions when creating a Cloud Dataproc cluster so that you can install the additional software you need.
Installing Zeppelin on Cloud Dataproc
We will go through the steps to do exactly that when we set up Zeppelin with Spark on Cloud Dataproc. Why Zeppelin? It’s an innovative web-based notebook that enables interactive data analytics.
With Zeppelin, you can create data-driven documents based on a variety of different backends, including Hadoop. It’s a great starting project, so let’s jump right into it.
Our Assumptions
- We will assume that you have created a new Cloud Platform Console project and that you have enabled billing for this project.
- We will need both Google Cloud Dataproc and Compute Engine APIs enabled.
- And finally, we will assume that you have installed the Google Cloud SDK and initialized gcloud.
Creating a Cloud Dataproc Cluster
Google provided a collection of initialization actions that we can use to install additional (but unsupported) Hadoop components when we create a cluster. For this example, we will use the Zeppelin initialization action.
To use an initialization action, we need to access the initialization action script in a Cloud Storage bucket.
We will not use the publicly-accessible gs://dataproc-initialization-actions Cloud Storage bucket as instructed in the README. At the time of writing, the version of the Zeppelin initialization action script is outdated. If we were to create a cluster with it, we would encounter errors. Let’s upload the script to our own Cloud Storage bucket instead.
$ git clone https://github.com/GoogleCloudPlatform/dataproc-initialization-actions.git Cloning into 'dataproc-initialization-actions'... remote: Counting objects: 267, done. remote: Total 267 (delta 0), reused 0 (delta 0), pack-reused 266 Receiving objects: 100% (267/267), 89.24 KiB | 63.00 KiB/s, done. Resolving deltas: 100% (88/88), done. Checking connectivity... done. $ cd dataproc-initialization-actions/apache-zeppelin/ $ gsutil mb gs://cloudacademy/ Creating gs://cloudacademy/... $ gsutil cp zeppelin.sh gs://cloudacademy/ Copying file://zeppelin.sh [Content-Type=application/x-sh]... Uploading gs://cloudacademy/zeppelin.sh: 4.47 KiB/4.47 KiB
Next, we will issue the gcloud command to set up a Cloud Dataproc cluster.
$ gcloud dataproc clusters create spark-zeppelin \
> --initialization-actions gs://cloudacademy/zeppelin.sh \
> --initialization-action-timeout 15m
Waiting on operation [projects/operating-spot-133003/regions/global/operations/cdf1fadd-032d-4261-9520-c2f55f8c46fa].
Waiting for cluster creation operation...done.
Created [https://dataproc.googleapis.com/v1/projects/operating-spot-133003/regions/global/clusters/spark-zeppelin].
clusterName: spark-zeppelin
clusterUuid: f05a9f22-5ee6-48c8-83d3-7079e2d1d834
config:
configBucket: dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia
gceClusterConfig:
networkUri: https://www.googleapis.com/compute/v1/projects/operating-spot-133003/global/networks/default
serviceAccountScopes:
- https://www.googleapis.com/auth/bigquery
- https://www.googleapis.com/auth/bigtable.admin.table
- https://www.googleapis.com/auth/bigtable.data
- https://www.googleapis.com/auth/cloud.useraccounts.readonly
- https://www.googleapis.com/auth/devstorage.full_control
- https://www.googleapis.com/auth/devstorage.read_write
- https://www.googleapis.com/auth/logging.write
zoneUri: https://www.googleapis.com/compute/v1/projects/operating-spot-133003/zones/asia-east1-a
initializationActions:
- executableFile: gs://cloudacademy/zeppelin.sh
executionTimeout: 900.000s
masterConfig:
diskConfig:
bootDiskSizeGb: 500
imageUri: https://www.googleapis.com/compute/v1/projects/cloud-dataproc/global/images/dataproc-1-0-20160516-190717
instanceNames:
- spark-zeppelin-m
machineTypeUri: https://www.googleapis.com/compute/v1/projects/operating-spot-133003/zones/asia-east1-a/machineTypes/n1-standard-4
numInstances: 1
softwareConfig:
imageVersion: '1.0'
properties:
distcp:mapreduce.map.java.opts: -Xmx2457m
distcp:mapreduce.map.memory.mb: '3072'
distcp:mapreduce.reduce.java.opts: -Xmx4915m
distcp:mapreduce.reduce.memory.mb: '6144'
mapred:mapreduce.map.cpu.vcores: '1'
mapred:mapreduce.map.java.opts: -Xmx2457m
mapred:mapreduce.map.memory.mb: '3072'
mapred:mapreduce.reduce.cpu.vcores: '2'
mapred:mapreduce.reduce.java.opts: -Xmx4915m
mapred:mapreduce.reduce.memory.mb: '6144'
mapred:yarn.app.mapreduce.am.command-opts: -Xmx4915m
mapred:yarn.app.mapreduce.am.resource.cpu-vcores: '2'
mapred:yarn.app.mapreduce.am.resource.mb: '6144'
spark:spark.driver.maxResultSize: 1920m
spark:spark.driver.memory: 3840m
spark:spark.executor.cores: '2'
spark:spark.executor.memory: 5586m
spark:spark.yarn.am.memory: 5586m
spark:spark.yarn.am.memoryOverhead: '558'
spark:spark.yarn.executor.memoryOverhead: '558'
yarn:yarn.nodemanager.resource.memory-mb: '12288'
yarn:yarn.scheduler.maximum-allocation-mb: '12288'
yarn:yarn.scheduler.minimum-allocation-mb: '1024'
workerConfig:
diskConfig:
bootDiskSizeGb: 500
imageUri: https://www.googleapis.com/compute/v1/projects/cloud-dataproc/global/images/dataproc-1-0-20160516-190717
instanceNames:
- spark-zeppelin-w-0
- spark-zeppelin-w-1
machineTypeUri: https://www.googleapis.com/compute/v1/projects/operating-spot-133003/zones/asia-east1-a/machineTypes/n1-standard-4
numInstances: 2
projectId: operating-spot-133003
status:
state: RUNNING
stateStartTime: '2016-06-07T09:35:33.783Z'
statusHistory:
- state: CREATING
stateStartTime: '2016-06-07T09:32:56.398Z'
By default, Cloud Dataproc clusters use n1-standard-4 machine type for the master and worker nodes. These are the standard instances with 4 virtual CPUs and 15GB of memory. You can change the defaults by specifying the relevant flags. See the gcloud dataproc clusters create documentation.
$ gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS spark-zeppelin-m asia-east1-a n1-standard-4 10.140.0.2 104.199.169.41 RUNNING spark-zeppelin-w-0 asia-east1-a n1-standard-4 10.140.0.4 104.199.160.183 RUNNING spark-zeppelin-w-1 asia-east1-a n1-standard-4 10.140.0.3 130.211.248.2 RUNNING
SSH to the Master Node
Now we can connect to the master node remotely. Instead of running ssh directly, we can issue the gcloud compute ssh spark-zeppelin-m command.
$ gcloud compute ssh spark-zeppelin-m WARNING: The private SSH key file for Google Compute Engine does not exist. WARNING: You do not have an SSH key for Google Compute Engine. WARNING: [/usr/bin/ssh-keygen] will be executed to generate a key. This tool needs to create the directory [/Users/eugeneteo/.ssh] before being able to generate SSH keys. Do you want to continue (Y/n)? Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /Users/eugeneteo/.ssh/google_compute_engine. Your public key has been saved in /Users/eugeneteo/.ssh/google_compute_engine.pub. The key fingerprint is: SHA256:xTjbTqWIfroXr670RWQkscOPfGdY6rzpi14WCoFI5Ko eugeneteo@eugeneteos-MacBook-Pro.local The key's randomart image is: +---[RSA 2048]----+ | .o o.. | | o . . . * | | o . . * = o | | . + % * | |. o S @ o | |. . ..O + | |E o ooB | | . +.=.o | | +**o=. | +----[SHA256]-----+ Updated [https://www.googleapis.com/compute/v1/projects/operating-spot-133003]. Warning: Permanently added 'compute.5792161037633137215' (ECDSA) to the list of known hosts. The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. eugeneteo@spark-zeppelin-m:~$
Spark’s Scala Shell
We will not cover the Spark programming model in this article, but we will learn just enough to start an interpreter on the command-line and to make sure it works. We will launch spark-shell on YARN.
$ spark-shell --master=yarn
16/06/07 09:53:32 INFO org.spark-project.jetty.server.Server: jetty-8.y.z-SNAPSHOT
16/06/07 09:53:32 INFO org.spark-project.jetty.server.AbstractConnector: Started SocketConnector@0.0.0.0:36325
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.1
/_/
Using Scala version 2.10.5 (OpenJDK 64-Bit Server VM, Java 1.8.0_72-internal)
Type in expressions to have them evaluated.
Type :help for more information.
16/06/07 09:53:38 INFO akka.event.slf4j.Slf4jLogger: Slf4jLogger started
16/06/07 09:53:38 INFO Remoting: Starting remoting
16/06/07 09:53:38 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@10.140.0.2:40692]
16/06/07 09:53:39 INFO org.spark-project.jetty.server.Server: jetty-8.y.z-SNAPSHOT
16/06/07 09:53:39 INFO org.spark-project.jetty.server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
16/06/07 09:53:39 INFO org.apache.hadoop.yarn.client.RMProxy: Connecting to ResourceManager at spark-zeppelin-m/10.140.0.2:8032
16/06/07 09:53:43 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl: Submitted application application_1465292021581_0001
[...]
scala> val data = sc.parallelize(1 to 100000)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> data.filter(_ < 100).collect()
res0: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99)
It worked!
Access the Zeppelin Notebook
Before we can access the Zeppelin Notebook, we will need to create a SSH tunnel to the master node.
$ gcloud compute ssh --ssh-flag="-D 31337" --ssh-flag="-N" --ssh-flag="-n" spark-zeppelin-m
Configure your web browser to use the SOCKS proxy localhost:31337.
Having done that, we can now access http://localhost:8080/.

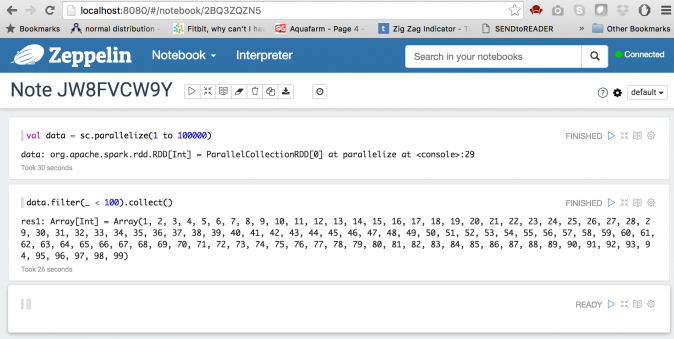
Great! The notebook works, too!
Terminating the Cloud Dataproc Cluster
Always remember to terminate your cluster after you have completed your work to avoid spending more money than you have planned. We are billed by the minute, based on the size of our cluster and the duration we ran our jobs.
$ gcloud dataproc clusters delete spark-zeppelin The cluster 'spark-zeppelin' and all attached disks will be deleted. Do you want to continue (Y/n)? y Waiting on operation [projects/operating-spot-133003/regions/global/operations/e2b88d41-e215-480e-a970-e6b49c0de574]. Waiting for cluster deletion operation...done. Deleted [https://dataproc.googleapis.com/v1/projects/operating-spot-133003/regions/global/clusters/spark-zeppelin]. $ gsutil -m rm -r gs://cloudacademy/ gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/ Removing gs://cloudacademy/zeppelin.sh#1465291266953000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/cluster.properties#1465291982908000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-m/dataproc-initialization-script-0_output#1465292128609000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-m/dataproc-startup-script_SUCCESS#1465292128628000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-m/dataproc-startup-script_output#1465292038813000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-w-0/dataproc-initialization-script-0_output#1465292016529000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-w-0/dataproc-startup-script_SUCCESS#1465292016563000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-w-0/dataproc-startup-script_output#1465292015001000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-w-1/dataproc-initialization-script-0_output#1465292016544000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-w-1/dataproc-startup-script_SUCCESS#1465292016575000... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/google-cloud-dataproc-metainfo/f05a9f22-5ee6-48c8-83d3-7079e2d1d834/spark-zeppelin-w-1/dataproc-startup-script_output#1465292014612000... Removing gs://cloudacademy/... Removing gs://dataproc-6dfb6ea8-847d-438c-befd-2883003f61e5-asia/...
What We’ve Learned
In this article, we have learned:
- How to set up a Cloud Dataproc cluster with Zeppelin.
- We have launched
spark-shellon YARN. - We have also set up a SSH tunnel to access the Zeppelin Notebook from the master node.
Related Courses
Data Management on Google Cloud Platform might be a place to start. It’s 26 minutes of data management goodness from David Clinton, an expert Linux Sysadmin.
For a guided instructional experience, check out a Cloud Academy Learning Path. We offer a free 7-day trial subscription with access all video courses, self-test quizzes, and labs. Our labs are a great tool for applying what you learned and testing your understanding in a live environment. Get started today!