![]()
Following AWS re:Invent 2017, we’ve counted more than 40 announcements of new or improved AWS services. Today, we’ll be talking about our picks for the new database and storage services that should be on your radar for 2018.
What’s New in the Database world?
If you’re into Magic Quadrants, here is what Gartner had to say about Operational Database Management Systems just one month before the announcements at AWS re:invent. It’s funny to see how quickly these documents become obsolete! 🙂
Although the largest majority of new services were related to AI and IoT, AWS also announced several new and exciting ways to manage and interact with existing databases, entirely new managed services, and even new optimized ways to fetch data from more traditional storage services such as S3 and Glacier.
The bad news is that four out of seven of the following announcements are still in preview. However, I’d gamble that they’ll be GA within a few months, and ideally before the end of Q1 2018. Let’s dig into the new database announcements.
1) Amazon Aurora Multi-Master (Preview)
Amazon Aurora is a cloud-native DBMS that is simultaneously compatible with well-known open-source databases (only MySQL and PostgreSQL for now), promises the same level of performance as most commercial databases, and is 10 times cheaper.
Amazon Aurora already comes with the ability to scale up to 15 read replicas across different Availability Zones and even multiple regions, default auto-scaling, and seamless recovery from replica failures. You can find out how it’s different from a regular MySQL cluster here, and you can see a series of interesting benchmarks here.
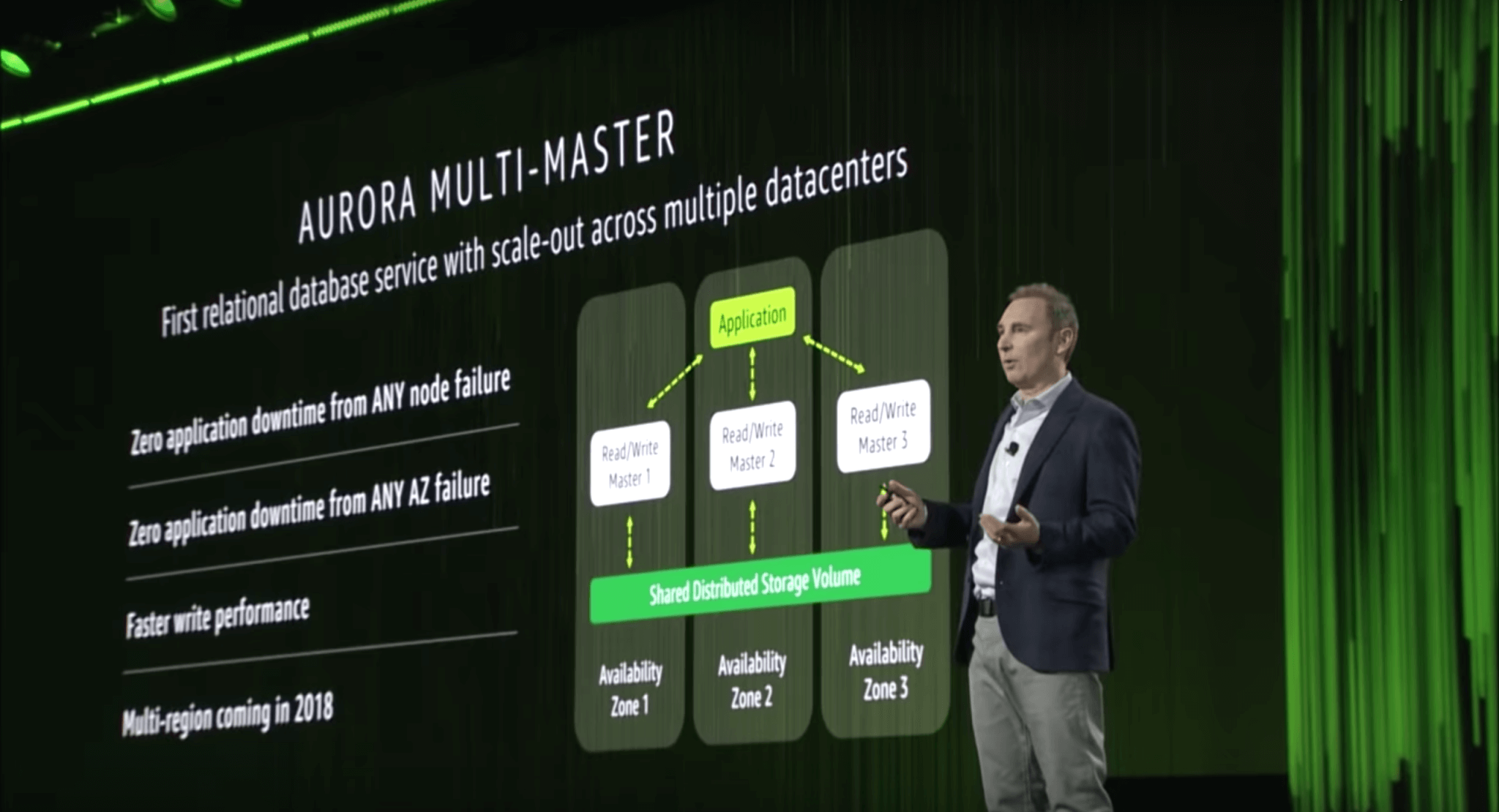
In Andy Jassy’s re:Invent keynote, he announced the Aurora Multi-Master, which allows Aurora clusters to scale out for both read and write operations by providing multiple master nodes across Availability Zones. This update enables both higher throughput and higher availability for Aurora clusters. Interestingly, Jassy pre-announced that Aurora will go multi-region as well, sometime in 2018.
Although the preview is only compatible with MySQL, I hope it will also be available for PostgreSQL once it becomes generally available.
In the meantime, you can apply for the preview here and get started with this Amazon Aurora Hands-on Lab on Cloud Academy.
2) Amazon Aurora Serverless (Preview)
Less than 60 seconds after announcing Aurora Multi-Master, Andy Jassy announced Aurora Serverless, which transforms how you think of databases for infrequent, intermittent, or unpredictable workloads.

Since Aurora Serverless can be enabled or disabled any time based on the current load of queries, in practice it is the very first on-demand relational database with a pay-per-second model. In fact, you are charged independently for compute capacity, storage, and I/O. In other words, Aurora Serverless is charged based on the total number of requests ($0.20 per million), the total size of the database ($0.10 per GB per month), and the total query execution time in seconds based on the concurrent Aurora Capacity Units ($0.06 per hour per ACU).
The main point here is that the number of ACUs will drop to zero as soon as you stop running queries. As long as Aurora Serverless is disabled, you are charged only for the database storage. If you are familiar with AWS Lambda, this is not too different from how Lambda Functions are charged (and storage tends to be pretty cheap).
Aurora Serverless is still in preview, and only for MySQL, but it is really promising for plenty of serverless use cases. First of all, it aligns with my favorite definition of serverless (i.e. it costs you “nothing” when no one is using it). Secondly, it will solve many problems related to serverless applications and relational databases such as connection pooling, networking, autoscaling, IAM-based credentials, etc. When combined with Aurora Multi-Master and Multi-Region, it will finally enable highly available serverless applications backed by a horizontally scalable relational database.
3) Amazon DynamoDB Global Tables (GA)
DynamoDB quickly became one of the most used NoSQL databases when it was launched back in 2012. It’s not the easiest database to work with when it comes to data design (learn more here), but it definitely solves most of the problems related to scalability, performance, security, extensibility, etc.
AWS announced and released the first tools and building blocks to enable DynamoDB cross-region replication back in 2015 (i.e. cross-region replication Java library and DynamoDB Streams). However, setting everything up manually was still kind of cumbersome, especially when considering more than two or three regions.

The newly announced DynamoDB Global Tables will take care of that complexity for you by enabling multi-master and multi-region automatic replication. This is incredibly powerful, especially if you are designing a single-region serverless application backed by API Gateway, Lambda, and DynamoDB.
With just a few clicks, you can easily enable Global Tables, deploy your stack into multiple regions, perform some ACM and Route53 tricks, and finally obtain a multi-region serverless application.

The most interesting part is that you won’t need to rewrite your application code since DynamoDB will take care of IAM Roles, Streams, Functions, etc. Also, you will have access to both local and global table metrics.
On the other hand, only empty tables can become part of a global table, which means you can’t easily go multi-region with your existing DynamoDB tables.
Also, remember that removing a region from your Global Table will not delete the local DynamoDB table, which will be available until you actually delete it, but you won’t be able to re-add it to the Global Table either (unless it’s still empty). Basically, you have to carefully choose the regions of your Global Table before you start writing any data into it. We hope that someone will come up with a clever workaround soon.
4) Amazon DynamoDB On-Demand Backup (GA)
The ability to backup and restore DynamoDB tables used to require ad-hoc tools and workarounds, which often required a long time and impacted production database performance. AWS has finally announced a built-in mechanism to create full backups of DynamoDB tables and point-in-time restore capabilities.

Backups will be incredibly useful for handling both regulatory requirements and application errors. You can create backups on the web console or via API. Although there is no built-in way to automatically create periodic backups, our friends at Serverless Inc. have already developed a Serverless Framework Plugin to automate this task for you.
My favorite part is that on-demand backups will have absolutely no impact on the production database. I also like that they are instant operations thanks to how DynamoDB handles snapshots and changelogs. It’s worth noting that each backup will save your table’s data and your capacity settings and indexes. Also, both backups and restores are charged based on the amount of data ($0.10 per GB per month for backups, $0.15 per GB for restores).
The only bad news is that the point-in-time restore functionality will come later next year, while on-demand backups are available today.
5) Amazon Neptune (Preview)
Amazon Neptune is the only new service on this list. It is a fully managed graph database and you can sign up for the limited preview here.

Neptune is intended for use cases where you need highly connected datasets that do not fit well into a relational model. If you already have a graph database, you’ll be able to migrate it into Neptune because it already comes with Property Graph and W3C’s RDF support. This means that you can query it with Gremlin (TinkerPop models) and SPARQL (RDF models).
Technically, Neptune can store billions of nodes and edges, and it guarantees millisecond latency and high availability and throughput thanks to 15 replicas across multiple AZs, VPC security, automated backups into S3, point-in-time restore capabilities, automatic failover, and encryption at rest.
In terms of pricing, Neptune is charged by the hour based on the instance type (db.t2.medium or db.r4.*), the total number of requests ($0.20 per million), the total amount of storage ($0.10 per GB per month), and the data transfer (the transfer to CloudFront is free!).
6) Amazon S3 Select (Preview)
Amazon S3 is the grandfather of every Amazon Service, and it keeps innovating how you think about data storage.
So many use cases adopted S3 as their preferred solution to build a data lake, and in many of those use cases, the ability to fetch the exact amount of data can drastically improve both performance and cost. There is an entire family of services that can automatically write into S3 (e.g. Amazon Kinesis Firehose) or query S3 objects without managing servers (e.g. Amazon Athena). However, most of the time the data you need is spread across multiple S3 objects; the only way to retrieve it is to fetch all of those objects.

S3 Select will optimize data retrieval performance and costs by enabling standard SQL expressions over your S3 objects. With S3 Select, you can write simple queries to extract a subset of the data. For example, you could fetch only specific sub-fields of every object or only fetch objects that satisfy a given condition.
This way, all of the filtering logic is performed directly by S3, and the client will receive a binary-encoded response. The advantage is that less data will need to be transferred, reducing both latency and costs of most applications. For example, Lambda applications that read S3 data will be able to reduce the overall execution time. Similarly, EMR applications will be able to use the corresponding Presto connector to drastically improve queries to S3 without changing the query code at all.
S3 Select is still in limited preview and you can sign up for the preview here. It already supports CSV and JSON files, whether gzipped or not. For now, encrypted objects are not supported, although I’m sure they will be once S3 Select becomes generally available.
My favorite part of S3 Select is that it will be supported natively by other services such as Amazon Athena and Redshift Spectrum. This means that it will automatically make your queries faster and cheaper.
7) Glacier Select (GA)
The same S3 limitations related to query efficiency hold for Amazon Glacier, with the additional constraint of waiting a few minutes (or hours, depending on the retrieval type).
Glacier Select is generally available and provides the same standard SQL interface of S3 Select over Glacier objects, effectively extending your Data Lake to cold storage as well. The best part is that Glacier Select will also be integrated with Amazon Athena and Redshift Spectrum. It sounds great, but I’m not sure how an Athena query will run for three hours waiting for Glacier data.
Glacier Select comes with the very same SQL interface, which allows you to reuse S3 Select queries once the objects have been archived into Glacier. Since Glacier won’t have to retrieve the entire archive, fetching archived data will become cheaper, and you still have the ability to choose the retrieval type (standard, expedited, or bulk).
Depending on the retrieval type, Glacier Select will be charged based on the total number of Select queries, how much data has been scanned, and how much data has been retrieved. Of course, retrieved data will be more expensive than scanned data (between 25% and 150% more expensive, depending on the retrieval type), while requests are charged in the order of $0.01 per request in case of expedited retrieval, $0.00005 per request for standard retrieval, and $0.000025 per request for bulk retrieval (price depends on the region, too).
What’s next?
I’m looking forward to experimenting with these new services and features myself, as I’m still waiting to be waitlisted for the limited preview. I’m quite excited by the possibility to painlessly create a global data layer, either with SQL or NoSQL.
As Amazon Aurora is becoming a sort of super cloud-native database, I’m especially curious about the many new features that will be announced. For example, as of re:Invent, it now supports synchronous invocations of AWS Lambda Functions in your MySQL queries.
In the meantime, I will play with DynamoDB Global Tables and build my first globally available serverless application backed by DynamoDB, Route53, Lambda, and API Gateway.
Of course, my favorite update in this list is Aurora Serverless, and I can’t wait to check it out and finally remove every fixed cost from my architecture (while still using our beloved SQL).
Catch up with more of our re:Invent 2017 recaps for Amazon Rekognition Video, Amazon GuardDuty, and AppSync here on the blog.
We’d love to hear about your favorite AWS re:Invent announcement and what you are going to build with it! Let us know in the comments!