![]()
Google Cloud Vision and Amazon Rekognition offer a broad spectrum of solutions, some of which are comparable in terms of functional details, quality, performance, and costs. This post is a fact-based comparative analysis on Google Vision vs. Amazon Rekognition and will focus on the technical aspects that differentiate the two services.
Quality will be evaluated more objectively with the support of data. Finally, the cost analysis will be modeled on real-world scenarios and based on the publicly available pricing.
The following table recaps the main high-level features and corresponding support on both platforms.
| Feature | Google Cloud Vision | Amazon Rekognition |
|---|---|---|
| Object Detection (labels) | ✓ | ✓ |
| Face Detection | ✓ | ✓ |
| Sentiment Detection (faces) | ✓ | ✓ |
| OCR | ✓ | |
| Logo/Landmark Detection | ✓ | |
| Nudity/Violence Detection | ✓ | |
| Face Comparison | ✓ | |
| Face Search | ✓ | |
| Object Detection (location) | ||
| Image Search | only faces | |
| Image Rendering |
Given the limited overlapping of the available features, we will focus on Object Detection, Face Detection, and Sentiment Detection.

Google Vision vs. Amazon Rekognition: Data Ingestion & I/O
Here, we will discuss how both services manage input data and outcoming results. We will focus on the types of data that can be used as input and the supported ways for providing APIs with input data.
Image Formats
Both services only accept raster image files (i.e. not based on vector graphics). Videos and animated images are not supported, although Google Cloud Vision will accept animated GIFs and consider only the first frame.
Amazon Rekognition’s support is limited to JPG and PNG formats, while Google Cloud Vision currently supports most of the image formats used on the Web, including GIF, BMP, WebP, Raw, Ico, etc.
Additional SVG support would be useful in some scenarios, but for now, the rasterization process is delegated to the API consumer.
Tests have not revealed any performance or quality issues based on the image format, although lossy formats such as JPEG might show worse results at very low resolutions (i.e. below 1MP).
Data Sources
Both Google Cloud Vision and Amazon Rekognition provide two ways to feed the corresponding API:
- Inlined Image: A base64-encoded representation of the input image, serialized as part of the API request.
- Cloud Storage: A simple reference to an image file hosted on Google Cloud Storage or Amazon S3, respectively.
The first method is less efficient and more difficult to measure in terms of network performance since the body size of each request will be considerably large. Despite its efficiency, the Inlined Image enables interesting scenarios such as web-based interfaces or browser extensions where Cloud Storage capabilities might be unavailable or even wasteful.
On the other hand, the Cloud Storage alternative allows API consumers to avoid network inefficiency and reuse uploaded files. Please note the following details related to Cloud Storage:
- Vendor-based: Google Cloud Vision only accepts files stored on Google Cloud Storage, while Amazon Rekognition only accepts files stored on Amazon S3. Cross-vendor storage is currently not supported.
- Object-level permission: The API consumer must be granted access to the referenced file(s).
- Object versioning: Is supported by Amazon Rekognition but not currently supported by Google Cloud Vision.
- Regional limitations: Amazon Rekognition will only accept files stored in the same region of the invoked API. Example: If you call the DetectLabels API in the eu-west-1 region, the S3 Object must be stored in a bucket created in the eu-west-1 region.
Neither Vision nor Rekognition accept external images in the form of arbitrary URLs. Such integration would simplify some use cases. It could be added as a third data source, although at a higher cost due to the additional networking required.
Batch Support
Processing multiple images is a common use case, eventually even concurrently. Batch support is useful for large datasets that require tagging or face indexing and for video processing, where the computation might exploit repetitive patterns in sequential frames. In addition to the obvious computational advantages, such information would also be useful for object tracking scenarios.
For now, only Google Cloud Vision supports batch processing.
Vision’s batch processing support is limited to 8MB per request. Therefore, a relatively large dataset of 1,000 modern images might easily require more than 200 batch requests. Also, the API is always synchronous. This means that once you have invoked the API with N requests, you have to wait until the N responses are generated and sent over the network.
A batch mode with asynchronous invocations would probably make size limitations softer and reduce the number of parallel connections. At the same time, it would shrink the number of API calls required to process large sets of images.
Video Support
Videos are not natively supported by Google Cloud Vision or Amazon Rekognition.
If we think of a video as a sequence of frames, API consumers would need to choose a suitable frame rate and manually extract images before uploading them to the Cloud Storage service.
Within AWS, API consumers may use Amazon Elastic Transcoder to process video files and extract images and thumbnails into S3 for further processing. Such a solution would be fully integrated into the AWS console, as Elastic Transcoder is part of the AWS suite.
On the other hand, GCP offers media solutions through official partners that are based on Google’s global infrastructure such as Zencoder, Telestream, Bitmovin, etc.
Native video support would definitely make things easier, and it would open the door to new video-related functionalities such as object tracking, video search, etc.
API Conventions
Both APIs accept and return JSON data that is passed as the body of HTTP POST requests.
While Google Cloud Vision aggregates every API call in a single HTTP endpoint (images:annotate), Amazon Rekognition defines one HTTP endpoint for each functionality (DetectLabels, DetectFaces, etc.).
Although AWS’s choice might seem more intuitive and user-friendly, the design chosen by Google makes it easy to run more than one analysis of a given image at the same time since you can ask for more than one annotation type within the same HTTP request.
API response sizes are somewhat similar for both platforms. Labeling responses with less than 10 labels always weigh less than 1KB, while each detected face always weighs less than 10KB.
Google Vision vs. Amazon Rekognition: Object Detection
The Object Detection functionality of Google Cloud Vision and Amazon Rekognition is almost identical, both syntactically and semantically. The API always returns a list of labels that are sorted by the corresponding confidence score. Vision’s responses will also contain a reference to Google’s Knowledge Graph, which can be useful for further processing of synonyms, related concepts, and so on.
Obviously, each service is trained on a different set of labels, and it’s difficult to directly compare the results for a given image.
That’s why we made our quality and performance analysis on a small, custom dataset of 20 images, organized into four size categories:
- Small: below 1MP
- Middle: below 2MP
- Large: below 4MP
- Huge: above 4MP
Each category contains five images with a random distribution of people, objects, indoor, outdoor, panoramas, cities, etc. The categorization is used to identify quality or performance correlations based on the image size/resolution.
Quality Analysis
Based on our sample, Google Cloud Vision seems to detect misleading labels much more rarely, while Amazon Rekognition seems to be better at detecting individual objects such as glasses, hats, humans, or a couch.
Overall, Vision detected 125 labels (6.25 per image, on average), while Rekognition detected 129 labels (6.45 per image, on average). Despite the lower number of labels, 93.6% of Vision’s labels turned out to be relevant (8 errors). Only 89% of Rekognition’s labels were relevant (14 errors).
It’s worth mentioning that Amazon Rekognition often clusters three equivalent labels together (“People”, “Person”, and “Human”) whenever a human being is detected in the image. By collapsing such labels into one, the total number of detected labels is 111 and the relevance rate goes down to 87.3%.
The following table compares the results for each sub-category.
| Category | Google Cloud Vision | Amazon Rekognition |
|---|---|---|
| Overall | 125 labels 93.9% Relevance |
111 labels 87.3% Relevance |
| Small | 28 labels 96.4% Relevance |
35 labels 88.5% Relevance |
| Middle | 20 labels 75% Relevance |
10 labels 100% Relevance |
| Large | 37 labels 94.5% Relevance |
31 labels 87% Relevance |
| Huge | 34 labels 100% Relevance |
35 labels 82.8% Relevance |
Despite a lower relevance rate, Amazon Rekognition always managed to detect at least one relevant label for each image. Instead, Google Cloud Vision failed in two cases by providing either no labels above 70% confidence or misleading labels with high confidence.
Please note that the reported relevance scores can only be taken in relation to the considerably small dataset and are not meant to be universal precision rates. By increasing the dataset size, relevance scores will converge to a more meaningful result, although even partial data show a consistent predominance of Google Cloud Vision. On the other hand, Amazon Rekognition seems to be more coherent regarding the number of detected labels and appears to be more focused on detecting individual objects.
One additional note related to rotational invariance: Non-exhaustive tests have shown that Google Cloud Vision tends to perform worse when the images are rotated (up to 90°). On the other hand, the set of labels detected by Amazon Rekognition seems to remain relevant, if not identical to the original results.
Google Vision vs. Amazon Rekognition: Face Detection
There were a few cases where both APIs detected nonexistent faces, or where some real faces were not detected at all, usually due to low-resolution images or partially hidden details.
Quality Analysis
Both services show detection problems whenever faces are too small (below 100px), partially out of the image, or occluded by hands or other obstacles. While the first two scenarios are intrinsically difficult because of missing information, the third case might improve over time with a more specialized pattern recognition layer.
Amazon Rekognition seems to have detection issues with black and white images and elderly people, while Google Cloud Vision seems to have more problems with obstacles and background/foreground confusion.
Also, Amazon Rekognition managed to detect unexpected faces, either faces that did not exist or those related to animals or illustrations. Illustrations and computer-generated images are special cases and both APIs haven’t been properly trained to manage them. However, they are probably not in the scope of most end-user applications. On the other hand, animals are not officially supported by either Vision or Rekognition, but Rekognition seems to have more success with primates, whether it’s intentional or not.
As well as for Object Detection, Amazon Rekognition has shown a very good rotational invariance. Although it’s not perfect, Rekognition’s results don’t seem to suffer much for completely rotated images (90°, 180°, etc.), while Vision stops performing well when you get close to a 90° rotation. Amazon’s deep learning models must have been intentionally trained to achieve rotational invariance, which is a particularly desirable feature for many scenarios.
We didn’t focus on other accuracy parameters such as location, direction, special traits, and gender (Vision doesn’t provide such data). Further work and a considerable dataset expansion may provide useful insight about face location and direction accuracy, although the difference of a few pixels is usually negligible for most applications.
Google Vision vs. Amazon Rekognition: Sentiment Detection (Faces)
Although both services can detect emotions, which are returned as additional landmarks by the face detection API, they were trained to extract different types of emotions, and in different formats.
Google Cloud Vision can detect only four basic emotions: Joy, Sorrow, Anger, and Surprise. The emotional confidence is given in the form of a categorical estimate with labels such as “Very Unlikely,” “Unlikely,” “Possible,” “Likely,” and “Very Likely.” Such estimates are returned for each detected face and for each possible emotion. If no specific emotion is detected, the “Very Unlikely” label will be used.
Amazon Rekognition can detect a broader set of emotions: Happy, Sad, Angry, Confused, Disgusted, Surprised, and Calm. It also identifies an additional “Unknown” value for very rare cases that we did not encounter during this analysis. The emotional confidence is given in the form of a numerical value between 0 and 100.
Quality Analysis
The limited emotional range provided by Google Cloud Vision doesn’t make the comparison completely fair. Psychological studies have shown that human behavior can be categorized into six globally accepted emotions: happiness, sadness, fear, anger, surprise, and disgust. The emotional set chosen by Amazon is almost identical to these universal emotions, even if Amazon chose to include calmness and confusion instead of fear.
This limitation is even more important when considering the wide range of emotional shades often found within the same image. Deciding whether a face is happy or surprised, angry or confused, sad or calm can be a tough job even for humans. A sentiment detection API should be able to detect such shades and eventually provide the API consumer with multiple emotions and a relatively granular confidence. Amazon Rekognition seems to behave this way.
Even when a clear emotion is hardly detectable, Rekognition will return at least two potential emotions, even with a confidence level below 5%. On the other hand, Vision is often incapable of detecting any emotion at all. This is partially due to the limited emotional range chosen by Google, but it also seems to be an intrinsic training issue. Overall, Amazon Rekognition seems to perform much better than Google Cloud Vision.
The following table summarizes the platforms’ performance for emotion detection.
| Images with … | Google Cloud Vision | Amazon Rekognition |
|---|---|---|
| […] at least 1 emotion | 60% | 100% |
| […] at least 2 emotions | 8% | 92% |
| […] at least 3 emotions | 0% | 76% |
| […] at least 1 correct emotion | 32% | 76% |
| […] no wrong emotions | 36% | 64% |
Google Vision vs. Amazon Rekognition: Pricing
Both services do not require any upfront charges, and you pay based on the number of images processed per month. Since Vision’s API supports multiple annotations per API call, the pricing is based on billable units (e.g. one unit of Object Detection, one unit for Face Detection, etc.). Also, both services include a free usage tier for small monthly volumes.
While Google Cloud Vision is more expensive, its pricing model is also easier to understand. Here is a mathematical and visual representation of both pricing models, including their free usage (number of monthly images on the X-axis, USD on the Y-axis).
 |
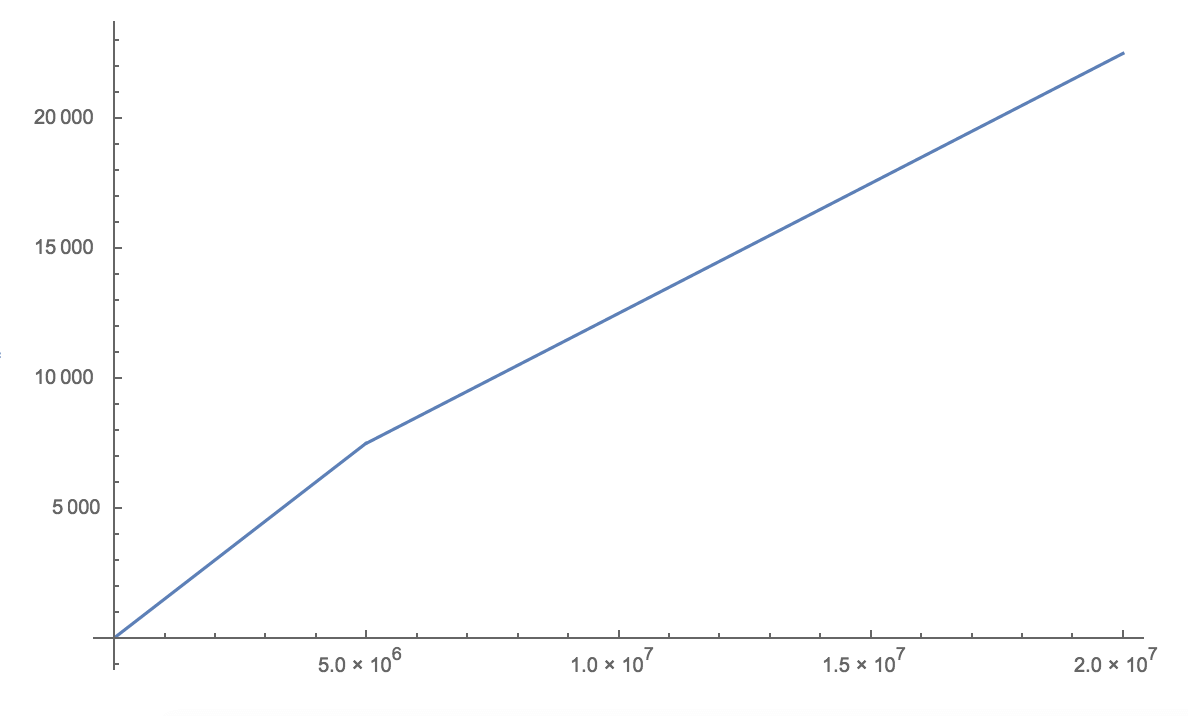 |
Google Cloud Vision pricing model (up to 20M images)
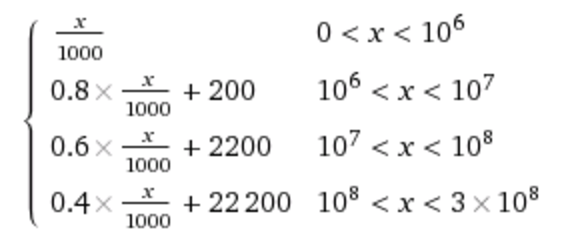 |
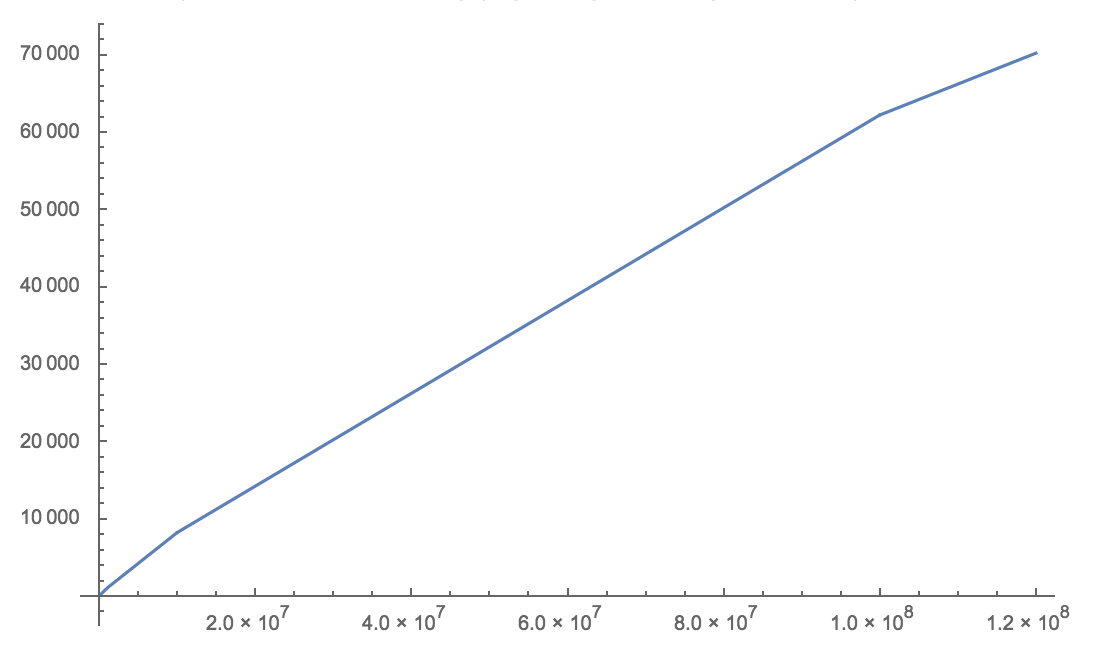 |
Amazon Rekognition pricing model (up to 120M images)
Free Usage
Although both services offer free usage, it’s worth mentioning that the AWS Free Tier is only valid for the first 12 months for each account. The Free Tier includes up to 5,000 processed images per month, spanning each Rekognition functionality.
On the other hand, Vision’s free usage includes 1,000 units per month for each functionality, forever.
Given the low volume allowed by both free tiers, such volumes are meant for prototyping and experimenting with the service and will not have any relevant impact on real-world scenarios that involve millions of images per month.
Real-world scenarios
The following charts show a graphical representation of the pricing models, including Vision’s free usage and excluding the AWS Free Tier. The X-axis represents the number of processed images per month, while the Y-axis represents the corresponding cost in USD.
The first three charts show the pricing differentiation for Object Detection, although the first two charts also hold for Face Detection. As mentioned previously, Google’s price is always higher unless we consider volumes of up to 3,000 images without the AWS Free Tier.




The situation is slightly different for Face Detection at very high volumes, where the pricing difference is roughly constant. Above 10M images, Google Cloud Vision is $2,300 more expensive, independently of the number of images (i.e. parallel lines).
Also, we should note that for volumes above 20M, Google might be open to building custom solutions, while Rekognition’s pricing will get cheaper for volumes above 100M images.


Finally, the same pricing can be projected into real scenarios and the corresponding budget. Each scenario is meant to be self-contained and to represent a worst-case estimate of the monthly load.
Note: All of the cost projections described below do not include storage costs.
For example:
- Only Face Detection: 20 thousand images
- Only Object Detection: 3 million images
- Only Face Detection: 20 million images
- Both Object Detection and Face Detection: 10 million images each
- Only Face Detection: 100 million images
- Both Object Detection and Face Detection: 50 million images each
| Scenario | Google Cloud Vision | Amazon Rekognition |
|---|---|---|
| Scenario 1 | $28.50 | $20 (w/o Free Tier) $15 (w/ Free Tier) |
| Scenario 2 | $4,500 | $2,600 |
| Scenario 3 | $16,500 | $14,200 |
| Scenario 4 | $23,000 | $14,200 |
| Scenario 5 | $64,500 | $62,200 |
| Scenario 6 | $87,000 | $62,200 |
The AWS Free Tier has been considered only for Scenario 1 since it would not impact the overall cost in the other cases ($5 difference).
It’s worth noting that Scenarios 3-4 and 5-6 cost the same within Amazon Rekognition (as they involve the same number of API calls), while the cost is substantially different for Google Cloud Vision. This is because Object Detection is far more expensive than Face Detection at higher volumes.
Overall, the analysis shows that Google’s solution is always more expensive, apart for low monthly volumes (below 3,000 images) and without considering the AWS Free Tier of 5,000 images.
Google Vision vs. Amazon Rekognition: Conclusion
Amazon Rekognition is a much younger product and it landed on the AI market with very competitive pricing and features. Its sentiment analysis capabilities and its rotation-invariant deep learning algorithms seem to out-perform Google’s solution.
Rekognition also comes with more advanced features such as Face Comparison and Face Search, but it lacks OCR and landmark/logo detection.
Google Cloud Vision is more mature and comes with more flexible API conventions, multiple image formats, and native batch support. Its Object Detection functionality generates much more relevant labels, and its Face Detection currently seems more mature as well, although it’s not quite perfect yet.
Google Cloud Vision’s biggest issue seems to be rotational invariance, although it might be transparently added to the deep learning model in the future. Similarly, sentiment detection could be improved by enriching the emotional set and providing more granular multi-emotion results.
Both services have a wide margin of improvement regarding batch/video support and more advanced features such as image search, object localization, and object tracking (video). Being able to fetch external images (e.g. by URL) might help speed up API adoption, while improving the quality of their Face Detection features will inspire greater trust from users.
Use case comparison
Based on the results illustrated above, let’s consider the main customer use cases and evaluate the more suitable solution, without considering pricing:
- Robotics: Enabling robots to see and understand their environment is a tough challenge and requires general-purpose understanding and very precise object detection. Unless a robot needs to interact with humans, identify them, and react to their emotions, Google Cloud Vision’s Object Detection will be a more suitable solution. Also, Vision will allow a robot to read with its OCR functionality, and eventually the robot will be able to understand speech with the new Google Cloud Speech API.
- Domotics: Home automation typically involves speech recognition capabilities, but it also requires the ability to identify and localize humans in order to allow/deny specific commands or allow access to certain rooms. Amazon Rekognition’s Face Detection and Face Comparison/Search will enable such scenarios.
- IoT: As with robots, Things would benefit from the ability to see and better understand their environment. Depending on the specific scenario, both Vision and Rekognition might be suitable. AWS’s native IoT platform would probably make the whole IoT application easier to design and scale up.
- Augmented Reality: AR applications usually require more specialized image analysis tools, but Object Detection and Face Detection are both useful building blocks for enabling highly interactive and smart applications. Native and real-time video processing and object tracking functionalities would make both services much more useful in this field. Google might be filling this gap sometime soon, perhaps in the next version of its Google Glass.
- Security & Surveillance: Similarly to domotics, surveillance typically requires identification and tracking capabilities. Even if Google Cloud Vision seems more mature for Face Detection, the lack of Face Comparison and Search is critical for this scenario. Amazon’s solution would be more suitable since it offers both face comparison and search. Also, Rekognition’s emotional accuracy might be useful in this context.
- Search Engines: The ability to look for specific objects or people/faces within an image (or a dataset of images) enables many additional scenarios. Amazon Rekognition already offers Face Indexing and Search, but it might add more types of “Collections” in the future. Also, its Object Detection functionality currently seems more focused on individual objects, despite being less accurate overall.
- Photo Recommendations: Suggesting pictures based on one’s preferences, activities, or emotional status would require a complex combination of label extraction, sentiment analysis, and machine learning combined into a powerful UX. The native support for image similarity or generic sentiment analysis (not based only on faces) would greatly improve this use case. For now, Vision would be preferable for algorithms based only on objects/labels, while Rekognition would allow you to also leverage accurate facial emotions, and smile and gender detection.
- In-store Sentiment Analysis: Detecting a customer’s opinion or emotion while still in the store enables many real-time marketing and customer support scenarios. While both services officially support facial emotion detection, Rekognition proved to be much more expressive and accurate than Vision.
- Brand Research: This scenario would require both Sentiment Analysis and Logo Detection capabilities. Google Cloud Vision supports Logo Detection, although this feature is not part of this analysis.
- Text Digitization (and handwriting): The ability to detect textual content in images is useful in many scenarios but especially for transforming scanned images into text documents. Google Cloud Vision’s OCR works pretty well with high-resolution images, and it also supports handwriting.
We’d like to hear from you. What is your favorite image analysis functionality and what do you hope to see next?