![]()
How Alfresco scaled to billions of documents on AWS
John Newton – Founder and, since 2005, CTO at Alfresco – used his AWS re:Invent presentation to talk about how Alfresco has been scaling to billions of documents and building apps capable of accessing that huge amount of content…all while moving from large data centers to cost-effective management on the Cloud.
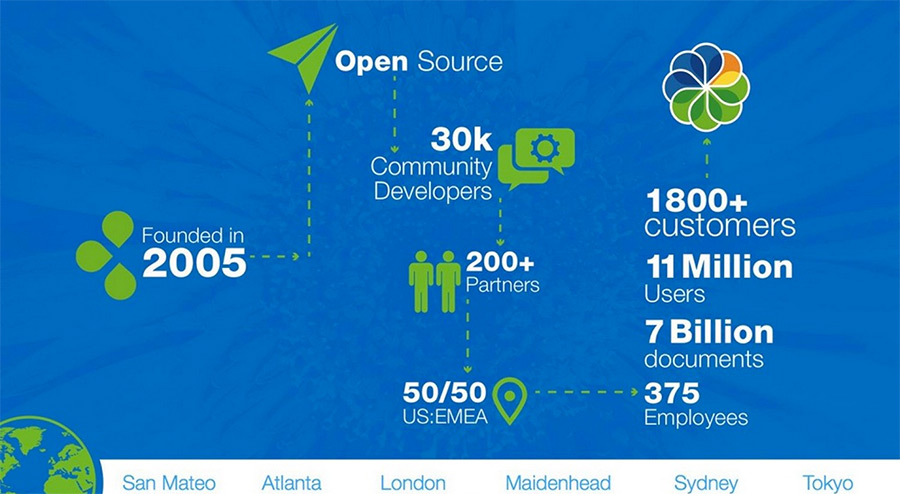
Alfresco completely embraced the open-source model and built a collaborative environment that currently supports more than 1800 customers, eleven million users, seven billion documents, and less than 400 employees.
Why is content at scale important?
The initial challenge was to store one billion documents, which was quite an impressive amount of data ten years ago – definitely over the petabyte scale. Today, of course, searching Google for the word “Amazon” will return that many pages, but things were different in 2005. Apparently someone tried configuring one million SharePoint servers back then, but of course that doesn’t work well.
The motivation behind this challenge can be identified in the incredible digital transformation that is driving huge flows of content: Cloud, Mobile, Social Networks, Big Data, etc., creating a whole new range of digital business. ECM (Enterprise Content Management), for instance, is a six billion dollar market.
So what are the main use cases for content at scale?
- enterprise document libraries.
- medical records.
- transaction and logistic records.
- government archives.
- claims processing.
- research and analysis.
- real-time video.
- discovery and litigation.
- loans and policies.
- IoT (Internet of Things).
Given this wide range of use cases, you can see why the numbers have grown so high: users need to search and retrieve documents, sync and share files, manage and archive all kinds of data content like records, images, and media. That’s why we have witnessed a conceptual transition from Content to Data, Files, and then EFSS. And that’s why John Newton admitted that working with such content architectures is a significant big data problem.
Since the main use case that drove Alfresco’s innovation was related to insurance companies, they also jumped on to the new Amazon Aurora database as soon as they could.
What is content at scale?
Content at scale is not just a matter of billion of documents. It also means dealing with a lot of geographically distributed users, who demand a certain level of read/write throughput.
Naturally, concurrency and volume size are serious and constant concerns, and large repositories in particular require both scaling up (clustered servers, databases, indexes, read replicas, etc) and scaling out (sharding, federation, replication, shared nothing, etc).
In the face of these issues, traditional approaches are limited in what they can provide for redundancy, elasticity, agility, geographic distribution, provisioning, and administration.
Why Amazon Aurora?
Alfresco’s solution is based on Amazon’s RDS, EBS, S3 and Glacier services. Their whole system is open source and developed in Java (you can read more about getting involved here).
John decided to move to Amazon Aurora for three main reasons:
- Aurora is highly available (sync/async replication).
- Aurora offers a significantly more efficient use of network I/O.
- Aurora is self-healing and fault-tolerant, with instant crash recovery.
To illustrate the kind of modifications he required to move his system to Aurora, John showed us a blank page: beyond a simple configuration switch, no modification was required.
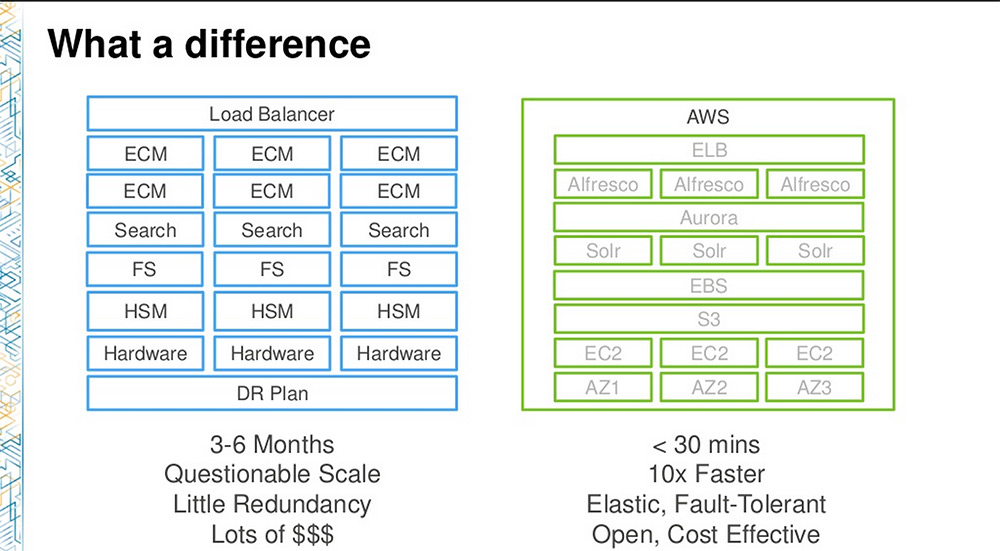
The Alfresco team also worked on some large scale benchmarking for concurrent loads and access (BM4), involving 1.2 billion documents, 500 simulated concurrent users (with Selenium) during 1 hour of constant load.
The system completed more than 15 million transactions, with a load-rate of 1200/s, 80% DB CPU load in bulk load, and Aurora’s indexes worked efficiently at 3.2TB. There were no size-related bottlenecks and John assured his audience that the very same infrastructure could sustain up to 20 billion documents.