![]()
Here at Cloud Academy, we use WordPress to serve our blog and product/public pages, such as the home page, the pricing page, etc.
Why WordPress?
With WordPress, the marketing and content teams can quickly and easily change the look & feel and the content of the pages, without reinventing the wheel.
State of the art
The first implementation of WordPress infrastructure was to deploy the whole code (core, theme and plugins) on an EFS storage, which basically is an NFS storage, attached to a couple of EC2 instances. Moreover, we installed W3 Total Cache plugin to handle full page cache and to serve static files (such as images, CSS, js, etc.) from a Cloudfront CDN.
Here is a simplified schema of our infrastructure:
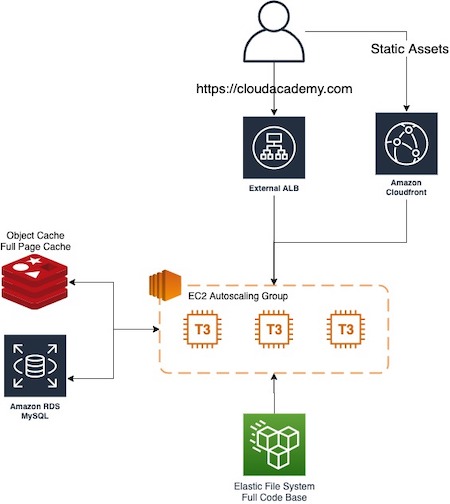
Considering this implementation, we found two different problems:
- The first is related to the EFS that doesn’t serve PHP files as fast as needed.
- The second is related to W3 Total cache plugins that, as previously mentioned, also handle the full page cache. This plugin retrieves a page from Redis cache but, despite Redis being a good choice to handle cached files, before getting the file from cache, W3 Total Cache needs to start the whole WordPress framework to understand the right object to get — bringing us back to the first problem.
With this approach, we waste a lot of time in getting the PHP files from the network file system and the cached page from Redis.
Refactoring
To solve the above-mentioned problems, we’ve rethought the whole infrastructure, moving it to a more standard Cloud Academy approach using Docker containers and ECS orchestrator.
Furthermore, we moved the CDN component to act as a full page cache instead of serving just the static assets.
Here is the schema of the new implementation:
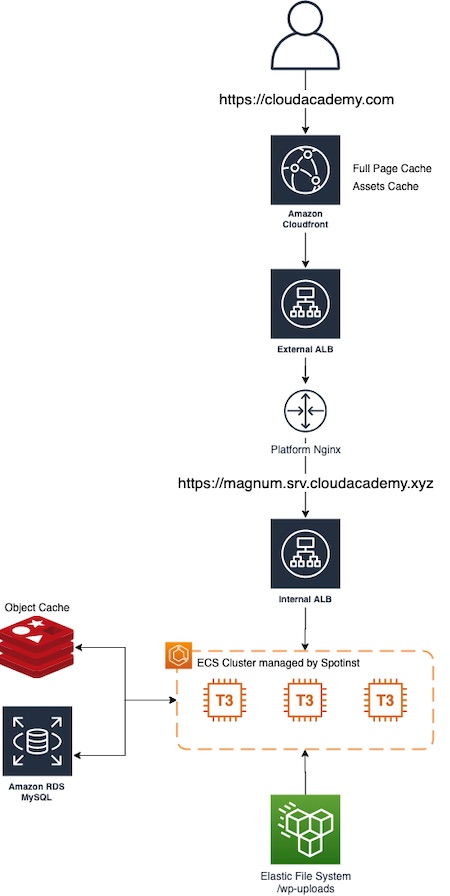
As you can see, the whole WordPress code is now built in a docker container (using our standard Jenkins pipeline) and then deployed to an ECS cluster managed by Spotinst.
However, we kept the EFS storage because the uploaded files from WordPress editors must be shared across all ECS containers.
The Docker build
One of our main goals was also to keep the minimum number of files versioned in the git repository. This means that the only versioned files for a WordPress project are related to custom themes and custom plugins.
To build the right docker image, we used the following approach:
Starting from the PHP image, the Dockerfile installs the wp-cli application and then downloads the WordPress core and all public plugins. To choose which plugins must be installed, the script reads a CSV file (that’s versioned) containing the list of all plugins and the relative version. In this way, when we want to install a new plugin, we just add it to the CSV file and then rebuild the Docker image.
The CDN
As shown in the schema, we moved the Cloudfront CDN to work as the main WordPress entry point. In this way, the “Hit” requests are handled directly by Cloudfront without loading the entire WordPress stack. In addition, Cloudfront gives us the ability to configure different behaviors depending on the requested page. More specifically, we can configure the cache TTL depending on the throughput that a single page has in order to maximize the cache performance (from 3 minutes to 10 minutes).
Unfortunately, CloudFront as a single entry point introduces a problem regarding the WordPress admin: as you can guess, we cannot have the admin pages cached. This is a problem because if we cache the admin pages, the editors can have unexpected behaviors with their sessions mixed together. To solve this issue, we created a new CDN behavior dedicated to the admin section that basically skips the cache, just using all headers and cookies as part of the cache key.
Now, what about the W3 Total Cache plugin? We decided to keep it installed because it will continue to optimize the cache miss from Cloudfront and the minification of static files.
Results
Of course, after the infrastructure refactoring, we made some benchmarks to understand the real benefit gained. This chart compares the performance of the old infrastructure versus the new:
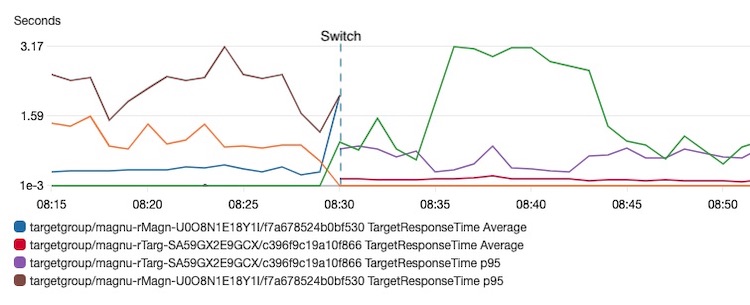
In the chart, the blue, brown and orange lines are related to the old infrastructure and the green, purple and red lines to the new infrastructure.
First of all, notice how the average response time of the new infrastructure (red line) is about half of the old one (blue line). But the very big improvement is on the 95 percentile brown line vs. purple line. This means that, thanks to the new infrastructure, 95% of requests are now served in less than a second.
Another effect that we measured with the ‘ab’ tool is the increase in throughput. We can now handle about twice as many requests than before using the same hardware configuration.
Considering the EFS usage, as you can see in the following image, the throughput that the file system must handle is now significantly lower than the old infrastructure (except for the switch moment, where there was a spike caused by all Cloudfront cache miss requests). This allowed us to decrease the EFS provisioned throughput which, of course, means a cost savings.
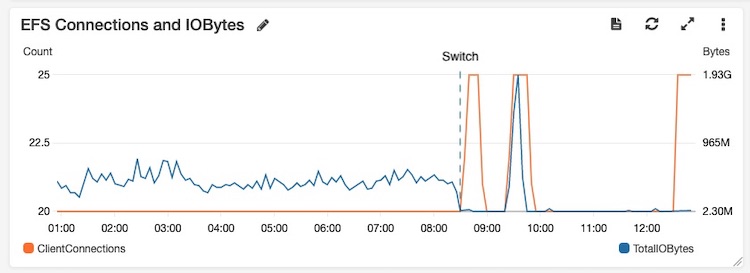
In addition, the time needed to scale up in case of a spike is considerably lower because we simply need to add new extra containers to the ECS service to handle new requests.
What’s next?
After this refactoring, which mainly focused on infrastructure, we are fully aware that most of the time the major issues are at the application level. So we are investigating how to refactor the WordPress front end, replacing it with a react app (like the rest of our platform), using either Next.js or Gatsby, in order to completely avoid the load of the WordPress framework except when serving API requests.