![]()
From the 22 new features released by AWS today at re:invent 2017, Amazon Rekognition Video stood out to me as the interesting “quiet achiever” I want to tell you about.
Amazon Rekognition Video brings object and facial recognition to live and on-demand video content. With this innovative new service, you can moderate and even replace parts of video content.
I know what you’re thinking. Does this mean we could replace an annoying object/person/presenter in a video with something more interesting? It’s all new, but potentially, yes. The Amazon Rekognition Video description lists object or person tracking as a feature of this new service. Imagine if we could replace an object/person/presenter with something ELSE in EVERY video we saw? Now THAT is getting interesting!
Let’s open the box and take a look.
Amazon Rekognition Video
Amazon Rekognition is based on a deep learning neural network model. The Amazon Rekognition Image processing service was released at re:invent 2016. According to Andy Jassy in today’s presentation, adoption of the Amazon Rekognition service has been high in the AWS customer base, and the feedback highlighted an interest in having Rekognition features available for video content.
Amazon Rekognition Video is the latest addition to the Amazon Rekognition service, and it’s generally available as of today.
Let’s start exploring what we can do with it. Opening the service in the AWS console, my first observation was that I needed to change regions! Amazon Rekognition Video is currently only available in the US East, US West, and EU regions.
On arrival in the console, we get an intro to the Amazon Rekognition engine. The Rekognition service identifies objects in images and presents a description of each image as metadata in JSON format. We get the label object, the coordinates, the timestamp, and an “accuracy” score for each label returned as a percentage. A label could be an object, a landmark, or even a face / facial gesture. (More on that aspect of Amazon Rekognition Video soon).
First, let’s do a quick hands-on recap of what Amazon Rekognition does and how it does it. In the first image I sent to Rekognition (below), Amazon Rekognition recognizes me, the “human” / “male” and the “dog” / ” border collie”.
Indy the border collie is half obscured in this difficult scene, which was no problem for the Amazon Rekognition service.
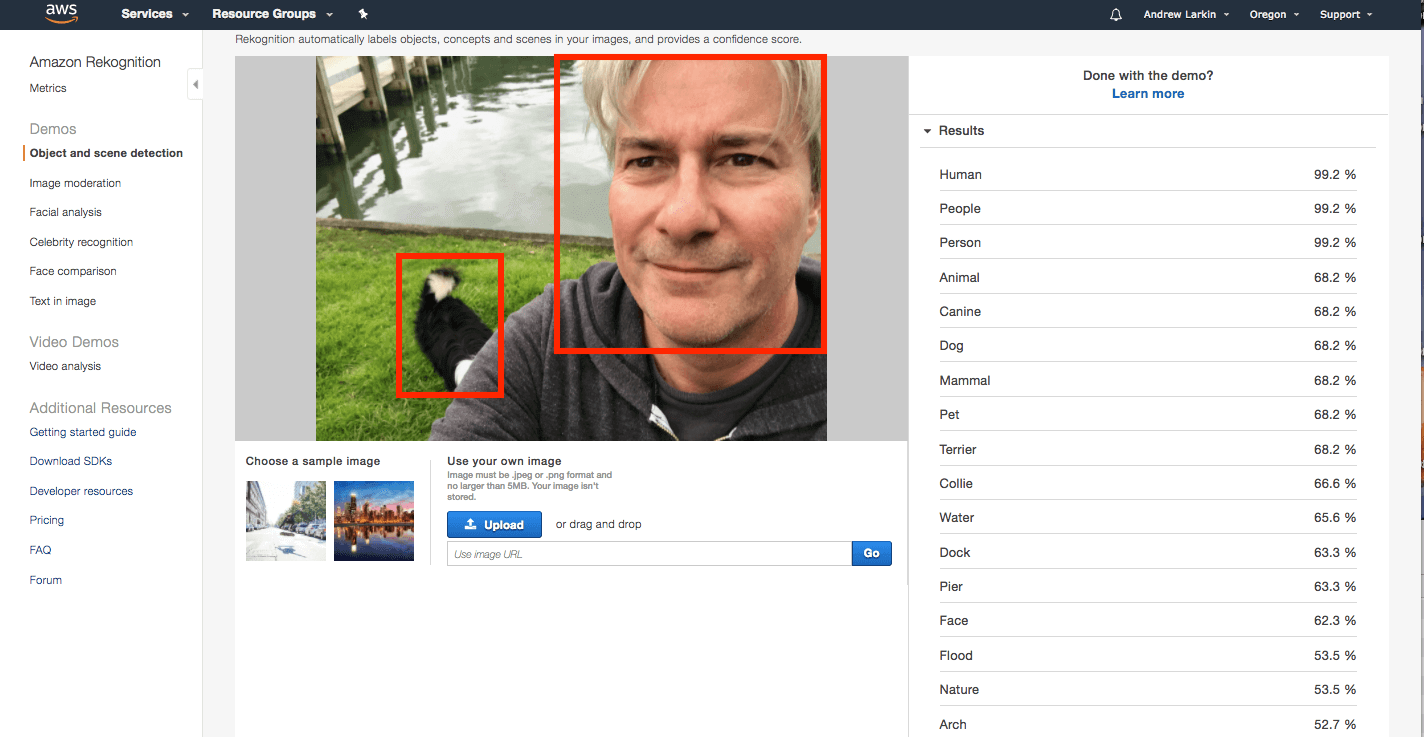
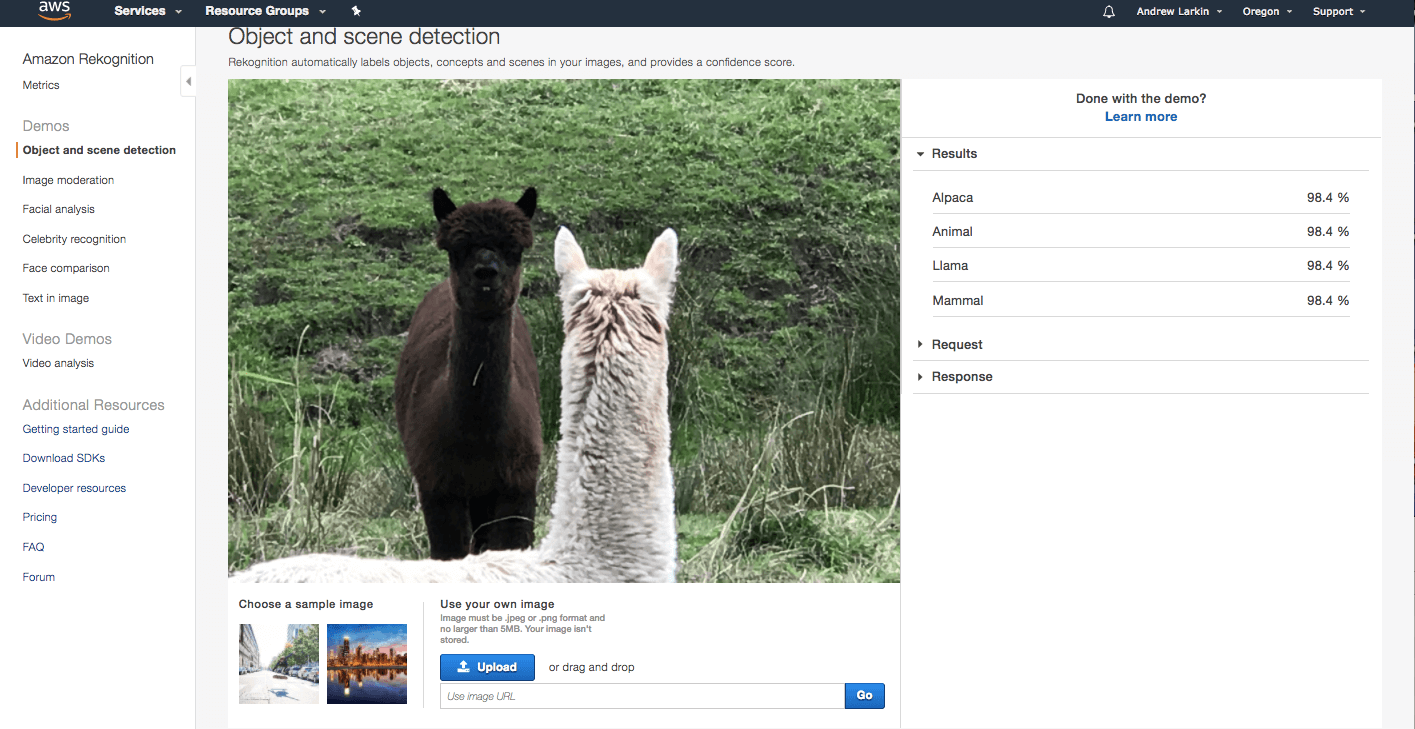
Rekognition did extremely well to recognize all of the objects in this difficult photo. I was very impressed. So, I threw it another rather difficult challenge: double llamas.
Rekognition just calmy recognizes “Alpaca” and “Llama” in this confusing shot. Wow. I am getting excited about this!
Just one more small test. Let’s see how Amazon Rekognition handles the “activity” label of the “dog” (Indy – my Border Collie) “swimming” in the blue-green New Zealand “ocean.”
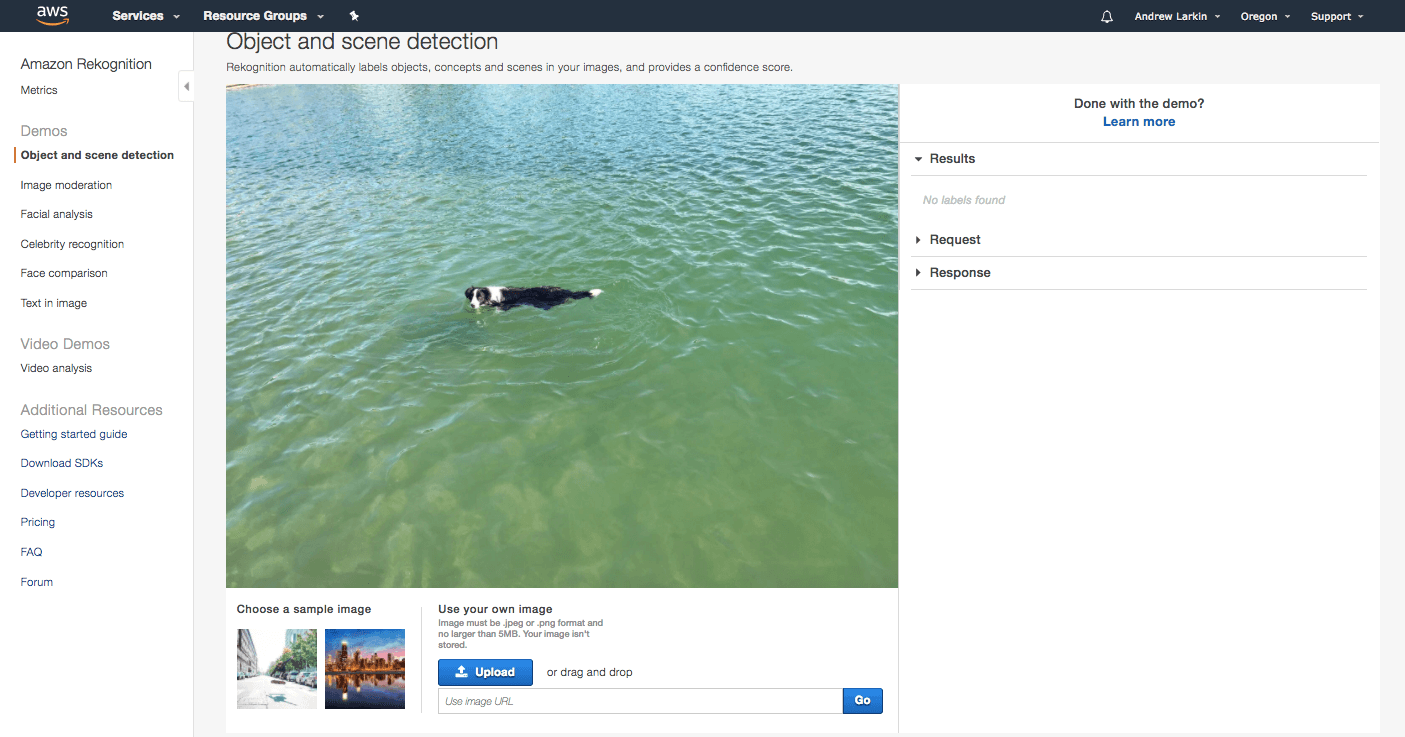
Ok, it didn’t. Rekognition returned no objects from this image! Ok, maybe that was too tough. Rekognition has worked quickly and seamlessly with every other image, so time to see how we can use Amazon Rekognition Video to do something really meaningful.
Rekognition Video challenge: Label Detection
On to the next challenge. I have a lot of videos of Indy, my Border Collie, swimming in the sea. She is an incredible swimmer, which is rare for a Border Collie. When Indy swims, she stands around on the pier for a long time before jumping in. As a result, it can be difficult to find the point in the video when she does jump in, which is, of course, the part people want to see.
I want to be able to identify and label the point where she hits the water. If Rekognition gets this right (understanding labels and the API), then we move on to celebrities and replacing people!
Time to access Rekognition Video via the console and then the CLI. I’ll share a few things I learned before getting started.
First: You need to have your video content in an S3 bucket within one of the supported regions.
Second: Amazon Rekognition Video processing is feature rich. So, let’s get into the full power of this amazing beast one step at a time. We’ll start by understanding Rekognition labels, then we can process a video and request the labels Rekognition returns to us. Next, we will use that information to execute an event. In our next lesson, we will explore facial recognition and tracking!
Most of your interactions will be through the AWS Command Line Interface (CLI). The AWS console can give you a basic visual representation of your outputs, which can be really helpful, so let’s run this first.
I uploaded a series of videos and asked Rekognition to process them.
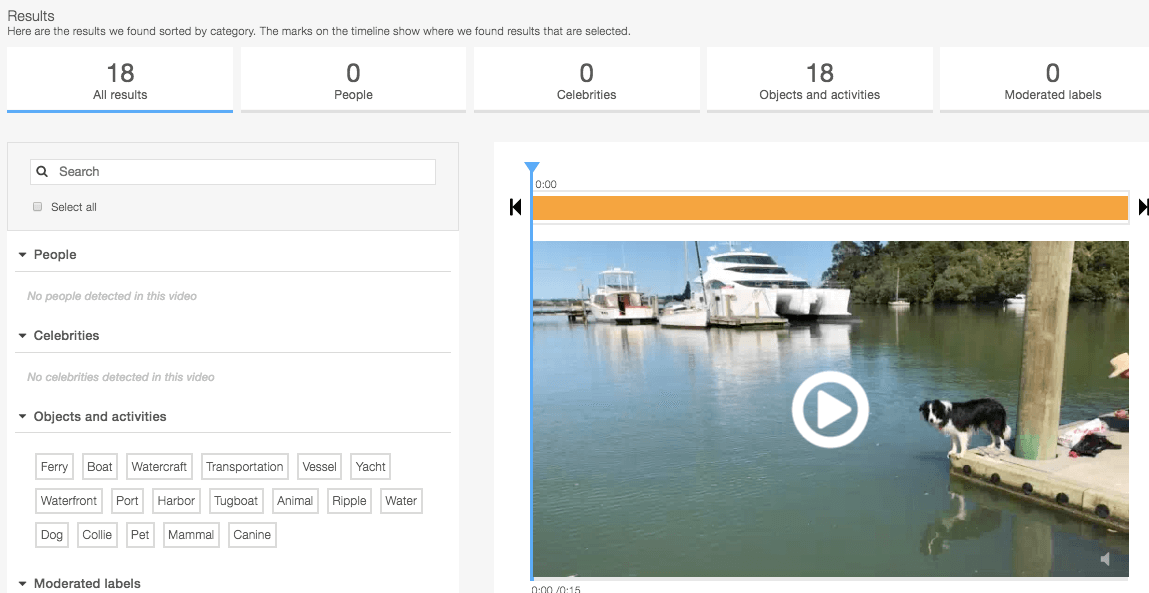
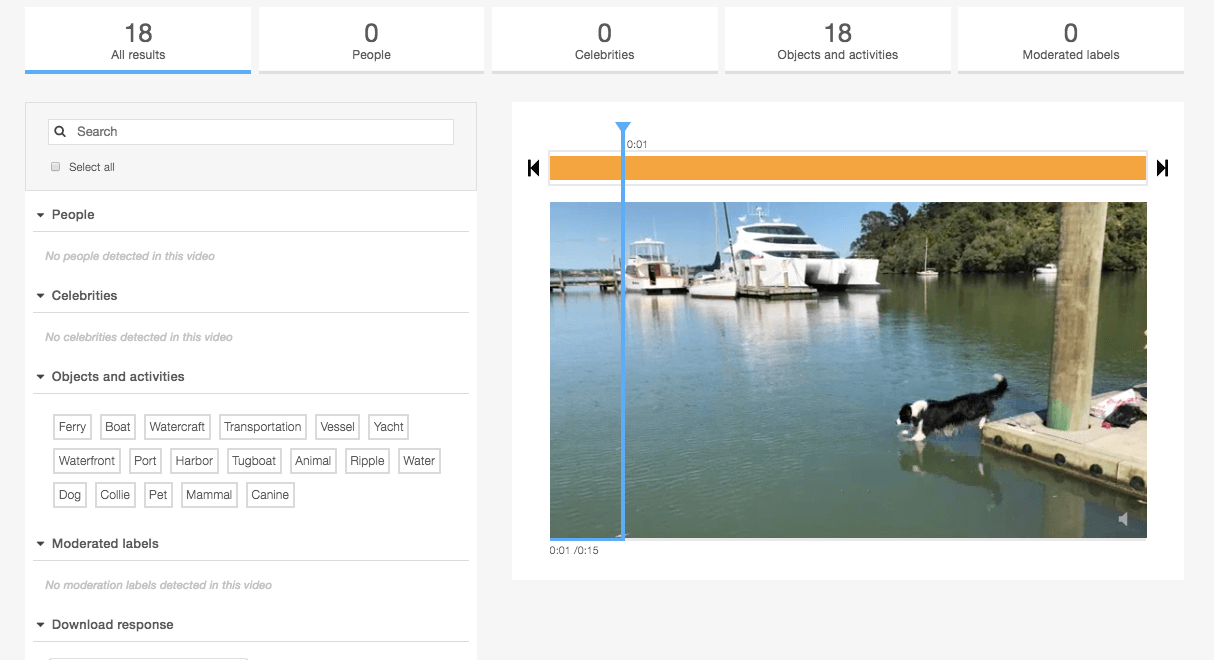
Rekogniton quickly summarizes the events, labels, and sentiment from the videos using its built-in processing engine. The process is fast, and I can immediately see the tags recognized / generated in the left-hand panel.
To see what else we can do with the API, we’ll interact with it using the CLI. There is always a little bit of set up required before using the API.
Here are the steps I try to remember when starting an Amazon Rekognition Video project:
- Create or have access to an S3 bucket in a supported region (currently the list is limited to the US East, US West, and EU regions, but that will change)
- Upload a video file in a supported format (most formats are supported; a short mp4 is good)
- Create an IAM role and give Rekognition Video access to multiple SNS topics. Copy the Amazon Resource Name (ARN)
- Create an Simple Notification Service topic. Add AmazonRekognition as a prefix to the topic
- Copy the topic ARN
- Create an SQS standard queue. Copy the queue ARN
- Subscribe the SQS queue to your SNS topic
From the console, we can call Rekognition and start processing our video.
aws rekognition start-label-detection –video S3Object={Bucket=”bucketname”,Name=”indy_swimming.mp4″} \
–endpoint-url Endpoint \
–notification-channel “SNSTopicArn=TopicARN,RoleArn=RoleARN” \
–region us-east-1 \
–profile RekognitionUserWeCreated
To start the detection of labels in a video, we call StartLabelDetection.
{
“Video”: {
“S3Object”: {
“Bucket”: “bucketname”,
“Name”: “indy_swimming.mp4”
}
},
“ClientRequestToken”: “LabelDetectionToken”,
“MinConfidence”: 40,
“NotificationChannel”: {
“SNSTopicArn”: “arn:aws:sns:us-east-1:nnnnnnnnnn:topic”,
“RoleArn”: “arn:aws:iam::nnnnnnnnnn:role/roleopic”
},
“JobTag”: “DetectingAllLabels”
}}
}
StartLabelDetection returns a job identifier (JobId)
{“JobId”:”270c1cc5e1d0ea2fbc59d97cb69a72a5495da75851976b14a1784ca90fc180e3″}
When the label detection operation has finished, Rekognition publishes a completion status to an Amazon Simple Notification Service (SNS) topic. The Amazon SNS topic must be in the same AWS region as the Rekognition Video endpoint that you are calling. The NotificationChannel also needs an ARN for a role that allows Rekognition Video to publish to the Amazon SNS topic.
{
“JobId”: “270c1cc5e1d0ea2fbc59d97cb69a72a5495da75851976b14a1nnnnnnnnnnnn”,
“Status”: “SUCCEEDED”,
“API”: “StartLabelDetection”,
“JobTag”: “DetectingAllLabels”,
“Timestamp”: 1510865364756,
“Video”: {
“S3ObjectName”: “indy_swimming.mp4”,
“S3Bucket”: “bucketname”
}
}
We can then call the detected labels with the method GetLabelDetection.
GetLabelDetection returns an array (Labels) that contains information about the labels detected in the video. The array can be sorted either by time or by the label detected by specifying the SortBy parameter eg “NAME.” “TIMESTAMP’ is the default sort parameter.
{
“JobId”: “270c1cc5e1d0ea2fbc59d97cb69a72a5495da75851976b14a1784ca90fc180e3”,
“MaxResults”: 20,
“SortBy”: “TIMESTAMP”
}
The JSON response lists all the labels identified by GetLabelDetection. Rekognition has identified that my video has water, a ripple, a boat, a ferry, and, a dog, which is a Collie. That is incredible! The two important ones for me are:
{“Label”:{“Confidence”:68.23069763183594,”Name”:”Collie”},”Timestamp”:200}
{“Label”:{“Confidence”:51.01799774169922,”Name”:”Ripple”},”Timestamp”:12000}
We’ll note that Rekognition did not detect swimming or jumping as activities. We do have the label “ripple,” which hopefully can help us identify when Indy jumps in the water.
Another point to keep in mind is that Rekognition only keeps the results of a video analysis operation for 24 hours. Results will be discarded after that window, so you need to write them to some type of persistent storage if you need to keep them.
Up next: In our next challenge, we will work through how to use this data to create a visual cue or move our playhead to the position just before where we record our “ripple” event.