![]()

How does Netflix operate on AWS?
Netflix has been on AWS since a devastating fire destroyed their own datacenter in 2010. By 2015, their Cloud migration was complete and, thanks to AWS, the scale they have achieved has been outstanding.
Josh Evans – Director of Operations Engineering at Netflix described the Netflix’s microservices architecture as a living organism, with critical components, internal flows, and failures. The infrastructure is composed of hundreds of completely decoupled and independent microservices involving thousands of daily production changes to many thousands of AWS instances.
Josh identifies two main challenges to achieving operational excellence:
Product innovation
In order to offer the best user experience – and therefore win their customers’ “moments of truth” (i.e., get them to watch more video content) – Netflix has to move and change fast.
Their innovation strategy involves the massive use of A/B tests on every facet of the product. During the last year, they ran more than 1,400 experiments (meaning at least 25 experiments running in parallel every day). Of course, the goal is to increase user engagement, and this explains why each user’s Netflix experience is sort of unique, both because of the customized recommendations they’re shown, and the unique combination of experiments.
Scale and complexity
Netflix currently handles hundreds of thousands of requests per second from about 60 countries. Their infrastructure runs multi-zone and multi-region, serving users from three different AWS regions. The only component running outside of AWS is their Netflix CDN, which currently covers about 37% of US Internet traffic.
Operations Engineering
Achieving operational excellence also involves a tough tradeoff between availability and rate of change (i.e. quality versus speed). Netflix is keen on trading some of their availability to enable fast change, and they approach the problem by means of continuous improvement of management, design, and function of operational environments. This kind of approach leads to greater quality, velocity, and competitive advantage.
The culture behind this choice can be summarized as “You build it, you run it”. It means 100% ownership, starting from designing, coding, building, testing and deploying…all the way to operating, configuring, monitoring, and responding (while doing it all globally!). They built their own software tools to enable this approach, like Spinnaker, Eureka, Hystrix, Atlas, and Vector (available on Github).
These tools are based on software engineering standards and advanced technologies:
- Anomaly detection: to identify anomalous patterns on short windows of time series events.
- Outlier detection and remediation: via unsupervised machine learning and clustering techniques.
- Canary release process: new versions of the software are available to a small percentage of the traffic, with automatic canary analysis.
- Unsupervised monitoring and decision making: take humans out of the equation and provide automatic alerts.
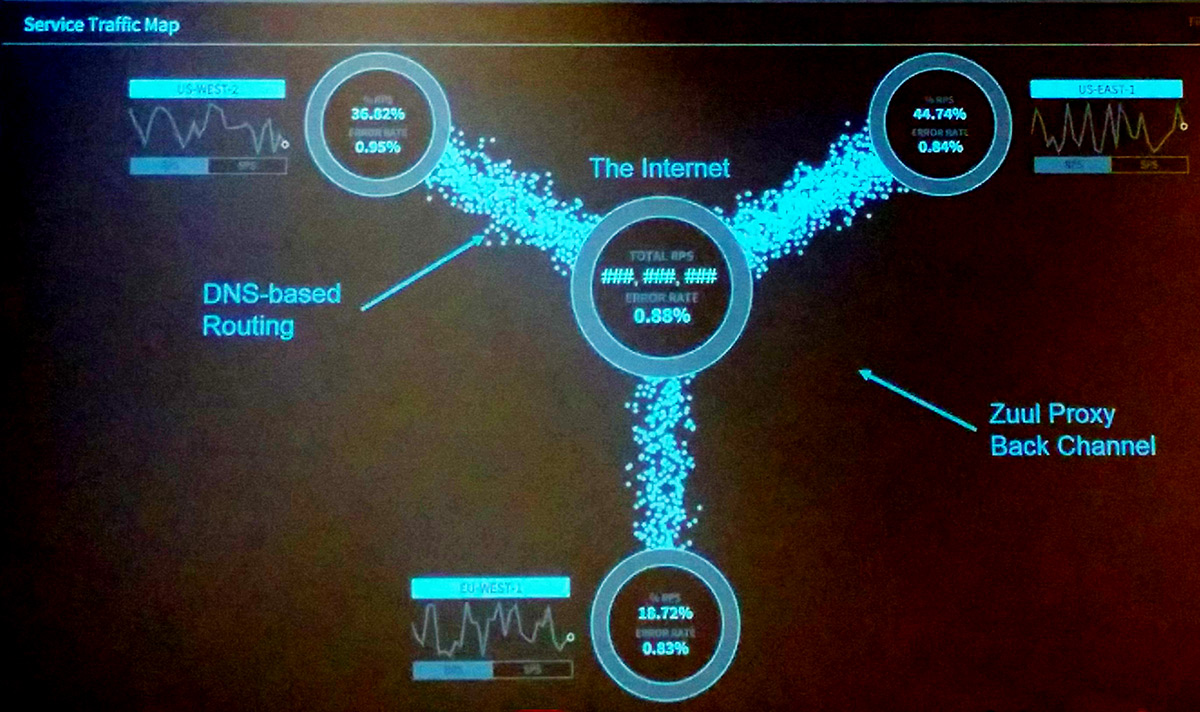
Chaos Engineering
Another important component of Netflix’s approach is chaos engineering. Being aware that components are going to fail, they work hard on building confidence in the system’s capability to withstand turbulent conditions (directly in production). You can find their SimianArmy on Github. By using FIT (Fault-injection Testing) they can simulate service failures, both on an instance- and region-level.
Netflix Keystone
Director of Engineering at Netflix, Peter Bakas – after proudly taking a picture of the crowd – explained how Netflix handles data streams of up to 8 million events per second.
Keystone handles about 550 billion events every day (more than 8 million events per second) and manipulates more than one petabyte of data, composed of hundreds of event types. Their data pipeline solution is based on open source projects, such as Apache Kafka, Apache Chukwa, and Apache Samza, besides Docker and MySQL.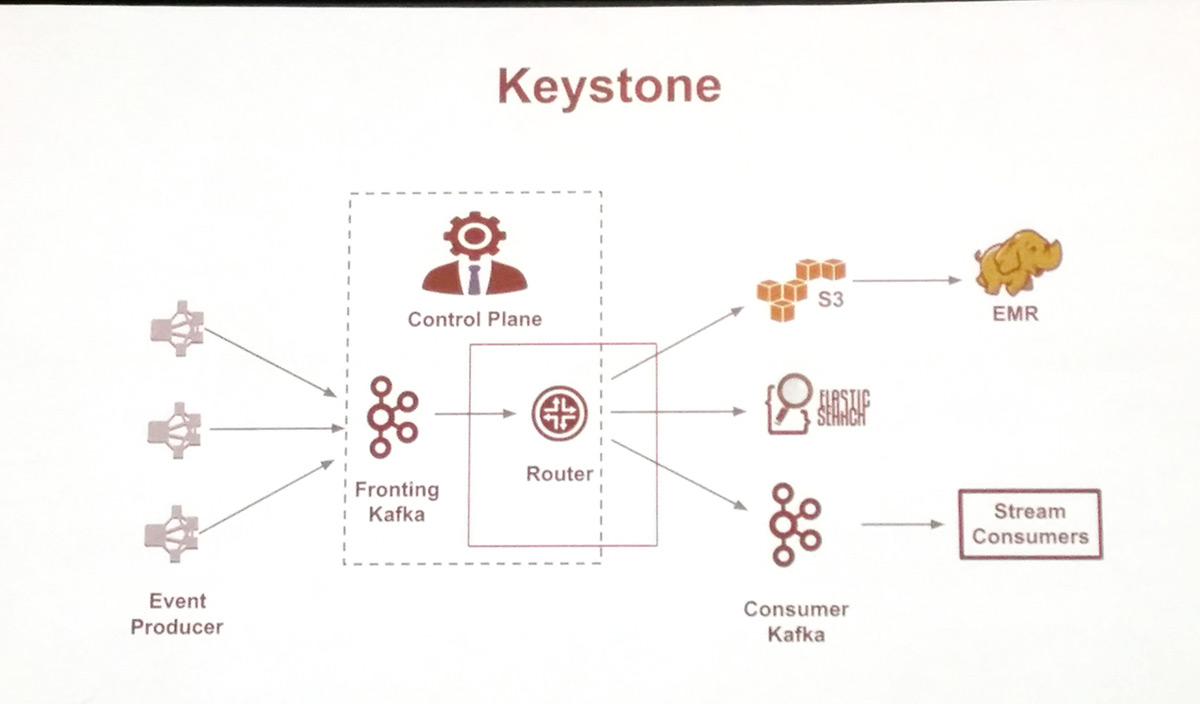
Netflix Core Team
Dave Hahn talked about how it feels and how it is possible for a few DevOps engineers to handle more than 37% of the US Internet. His team – the CORE team (Cloud Operations Reliability Engineering) – is responsible for crisis management, availability reporting, reliability best practices, AWS relationship, and operations education. It is mainly composed of crisis leaders and its goals are the following:
- Protect customer experience. This is crucial at Netflix and is the key point of each operation.
- Make failures unique. This means making errors happen only once, by identifying the real root of each problem and fixing it.
- Achieve constant improvement. This takes a lot of individual effort and can be helped along by incident reviews and by encouraging honest and open feedback.
Dave described the DevOps culture they have built based on the 100% ownership concept and made easier by the many tools developed for software engineers to enable easy ownership, including service discovery, solid communication, automated recovery, continuous deployment, and data persistence.
Insights are a key factor as well: Netflix records about 2.5 billion metrics every day and needed in-house tools to help them visualize and analyze relevant patterns, via prediction and automation.