![]()
A common question in the medical field is:
Is it possible to distinguish one class of samples from another, based on some set of measurements?
Research investigating this and related medical questions have spurred innovation in medicine and the application of statistical methods and machine learning for decades. In this post, we’ll address how to answer these questions using highly available, scalable, and easy-to-use cloud computing services that are included in Amazon Web Services (AWS).
We’ll start by guiding you through using Amazon Machine Learning to classify medical tumor samples as benign or malignant. Then, we’ll explore other machine learning services and how they could be used to investigate medical questions.
How to Diagnose Cancer with Amazon Machine Learning
This section investigates the medical question:
Is it possible to distinguish which breast mass samples are malignant given measurements from digital images of their cells?
The same question was asked by Dr. William Wolberg at the University of Wisconsin Hospital who created the data that is used in this section. During clinical trials, he extracted breast mass using a fine needle and took a variety of measurements of cell nuclei from magnified images similar to the following:
The diagnosis made by a pathologist is also recorded in the data.
The research aimed to find out if a computer could predict the same diagnosis in a way that is faster and less expensive. You can experiment with this yourself in a new hands-on lab on Cloud Academy, Diagnose Cancer with an Amazon Machine Learning Classifier
The Data
The raw data is hosted by the University of California, Irvine Machine Learning Repository. However, this guide uses a version that includes descriptive headings for each measurement field and a 0/1 encoding for the diagnosis.
Some examples of measurements taken of each nucleus include:
- Radius
- Perimeter
- Area
Because the images contain multiple cells, the data file uses average error, standard error, and a maximum of each group of measurements.
Binary Classification with Amazon Machine Learning
The diagnosis for a sample can be one of two classes: benign or malignant. In machine learning, this is referred to as binary classification. In AWS, you can use the Amazon Machine Learning (ML) service to build and train a predictive model for binary classification. To use Amazon ML, you typically perform the following four steps:
- Create a data source
- Create a model
- Perform an evaluation
- Make predictions using your model
If the evaluation results aren’t satisfactory, you might adjust some settings in the model. The default settings usually provide good results and are a good place to start. The remainder of this section will briefly cover each of the four steps for the medical question at hand.
Create an Amazon ML Data Source from the Medical Data
Amazon ML accesses data through data sources. A data source can reference data in Amazon Simple Storage Service (S3), Amazon’s Redshift data warehouse service, or Amazon Relational Database Service (RDS). All of these services are all HIPAA eligible services. For this experiment, S3 is the appropriate choice since the data exists in a file. All you need to do is upload the file to an S3 bucket where you have permission to create bucket policies:

You need permission to create bucket policies because Amazon ML creates a bucket policy for itself on your behalf to use the data.
When you access Amazon ML for the first time, you can launch a Standard setup wizard that steps you through creating a data source, model, and evaluation:

Following the setup wizard to create the data source, you:
- Provide the S3 path to the data file
- Tell Amazon ML that the first line in the data file contains column names
- Specify the diagnosis column as the target value to be predicted
- Select the id column as the patient identifier
- Review the details before creating the data source

In addition to referencing actual data, a data source gathers statistics about the data that are useful for building a model. Amazon’s elastically scalable compute infrastructure begins analyzing the data using multiple servers as soon as the data source is created. After processing completes, you can inspect the statistics for all the attributes in the data source. The medical data primarily contains numerical attributes (the measurements taken from images). Correlation to target, range, mean, median, maximum, minimum, and distributions are calculated for numerical attributes:

The distributions can be visualized using different bin widths automatically chosen by Amazon ML:

Create an Amazon ML Model for Binary Classification
The Amazon ML wizard automatically starts creating a model based on the data source you created. The data source target attribute determines the type of model that will be created:
- Binary: Binary classification model using a logistic regression learning algorithm
- Categorical: Multi-class classification model using a multinomial logistic regression learning algorithm
- Numerical: Regression model using a linear regression learning algorithm
Because the diagnosis column is binary, the created model will be a binary classification model.
In the wizard, use the Default training and evaluation settings as a starting point for your model:

The default settings will automatically generate a recipe for transforming the data source columns to features of the model. An example of transformation could be normalizing numerical columns to have zero mean and a standard deviation of one, or grouping ranges of values into bins instead of using the column values directly. The statistics that Amazon ML gathers for the data source are used to automatically determine which recipe is most likely to work well. The default settings also split the data into training and test sets for evaluation.
You can use custom settings for model training and evaluation. This is useful when you want more control over the model. For example, this could be helpful if the default settings don’t produce satisfactory results or if you know that a certain transformation or training parameter will work well. Custom settings allow you to control several training parameters including regularization type and amount to prevent overfitting the model to the training data. You can also specify an entirely separate data source for evaluation. The ability to specify separate data sources for validation allows you to perform more sophisticated validation schemes like k-fold cross-validation.
Completing the wizard will kick off model training. Once model training is complete, the evaluation will automatically begin. The evaluation uses the independent test set data that was not used during training. The model generates predictions for the unseen test data and compares the predictions to the actual diagnosis values
Explore the Performance of a Binary Classification Model
Once a model evaluation finishes, you can explore how the model performs in the evaluations view. Overall model performance is measured by the Area Under the Curve (AUC). AUC is a single metric that measures the overall accuracy of the model. The model combines measurements in the data in this experiment to achieve exceptionally good performance:

In most cases, an AUC around 0.7 or above is considered good.
AUC can’t show you the entire performance picture. The binary classification model outputs a number between zero and one where one is interpreted as predicted to be malignant and zero is interpreted as predicted to be benign. For values between zero and one, the interpretation depends on the setting of a threshold. Any value above the threshold is predicted as malignant and anything below is benign. The default value is 0.5. If the threshold of the model is poorly calibrated, a high AUC value means almost nothing.
The model evaluation includes a chart that is helpful for understanding the issue:

The threshold impacts the number of false positive (predicting positive when the actual diagnosis is negative) and false negative predictions. In general, a higher threshold reduces the number of false positives, while a lower threshold reduces the number of false negatives. In the medical domain, the cost of failing to diagnose a malignant tumor is greater than the cost of diagnosing a benign tumor as malignant. This can influence the threshold setting. Having Amazon ML compute the values for whatever threshold setting you choose and display the values in the visualization makes it easy to understand and difficult to make mistakes in interpreting the results.
Using the Model to Make Diagnoses
With a trained model in Amazon ML, you can make predictions in real time as well as in batches. For each type of prediction, you can use the Amazon ML console in your browser or an application programming interface (API) to programmatically make predictions. As an example, you can use the Try real-time predictions menu option in the Amazon ML console to make individual real-time predictions from inside your browser. From there, you can Paste a record to enter measurement values for each of the model attributes and have the model make a prediction:

You can use the following measurement sample:
000,13.24,14.06,87.16,563.3,0.09679,0.08229,0.06864,0.04791,0.1685,0.05966,0.2599,0.7686,2.158,22.56,0.008962,0.0136,0.02287,0.01415,0.0188,0.0023,15.11,19.26,99.7,711.2,0.144,0.1773,0.239,0.1288,0.2977,0.07259
The prediction is output on the page in JavaScript Object Notation (JSON):

The predictedLabel of 0 corresponds to a benign prediction. You can also see the predicted Scores, which shows the score computed before passing the threshold. Scores closer to zero or one are more confident predictions.
This concludes the guide on binary classification in AWS. You have seen how Amazon Machine Learning could have been used to easily perform the pioneering research that enabled a now common medical practice diagnosis procedure. However, there is much more to machine learning in AWS than binary classification in the Amazon Machine Learning service. The following section describes some of the services that can be used for medical research.
Other AWS Machine Learning Services
AWS provides a secure platform for research involving large amounts of data and collaborators across multiple sites. The elastic compute infrastructure allows you to scale to meet time constraints regardless of the size of the workload. Automated compliance services also enforce rules and policies required for handling sensitive data. In addition to these benefits for medical research, this section highlights a few AWS services that are useful for machine learning in the medical domain.
Amazon Machine Learning
As was briefly mentioned in the section above, multi-class classification and multi-variable linear regression are other types of models available in Amazon ML. Multi-class classification can play an important role when considering a broader research question. For example, given a set of symptoms, what is the most likely diagnosis? Regression models are useful for understanding the impact of multiple factors on an independent variable. This could be used to understand how age, weight, alcohol consumption, and amount of exercise influence blood pressure.
A hands-on lab in Cloud Academy walks you through the multi-class classification capabilities of Amazon ML. The lab uses inertial sensor measurements from a subject’s mobile phone to recognize the subject’s activity from a set of six possible activities. A lab to demonstrate the regression model capabilities in Amazon ML is currently in the works, so keep an eye on the latest AWS labs on Cloud Academy.
Amazon Deep Learning AMIs
Amazon maintains a set of Amazon Machine Images (AMIs) that allow you to launch servers, referred to as instances in AWS parlance, that have all of the most common machine learning frameworks pre-installed and ready to use. These AMIs are called Amazon Deep Learning AMIs.
Some of the frameworks included in the AMIs are Apache MXNet, the TensorFlow framework open-sourced by Google, and Caffe2 open-sourced by Facebook. The Amazon Deep Learning AMIs and the included frameworks are the subject of an entire course on Cloud Academy that will be released this month. A post on the AWS blog covers the story of a medical startup using AWS and the Amazon Deep Learning AMI to boost the early cancer detection rates by automatically processing CT scan imagery with advanced computer vision algorithms.
Amazon has a wide variety of instance types to choose from to hit the right price point for your application. Some instance types have graphics processing units (GPUs) attached to greatly reduce the time required to train deep learning models. You will be abl to experience the benefits of GPUs for machine learning first hand in a new hands-on lab on Cloud Academy. This lab will be available soon as part of our new learning path on Machine Learning in AWS (see more below). In addition to launching individual instances, Amazon provides a template to automatically provision a distributed computing cluster of deep learning instances:
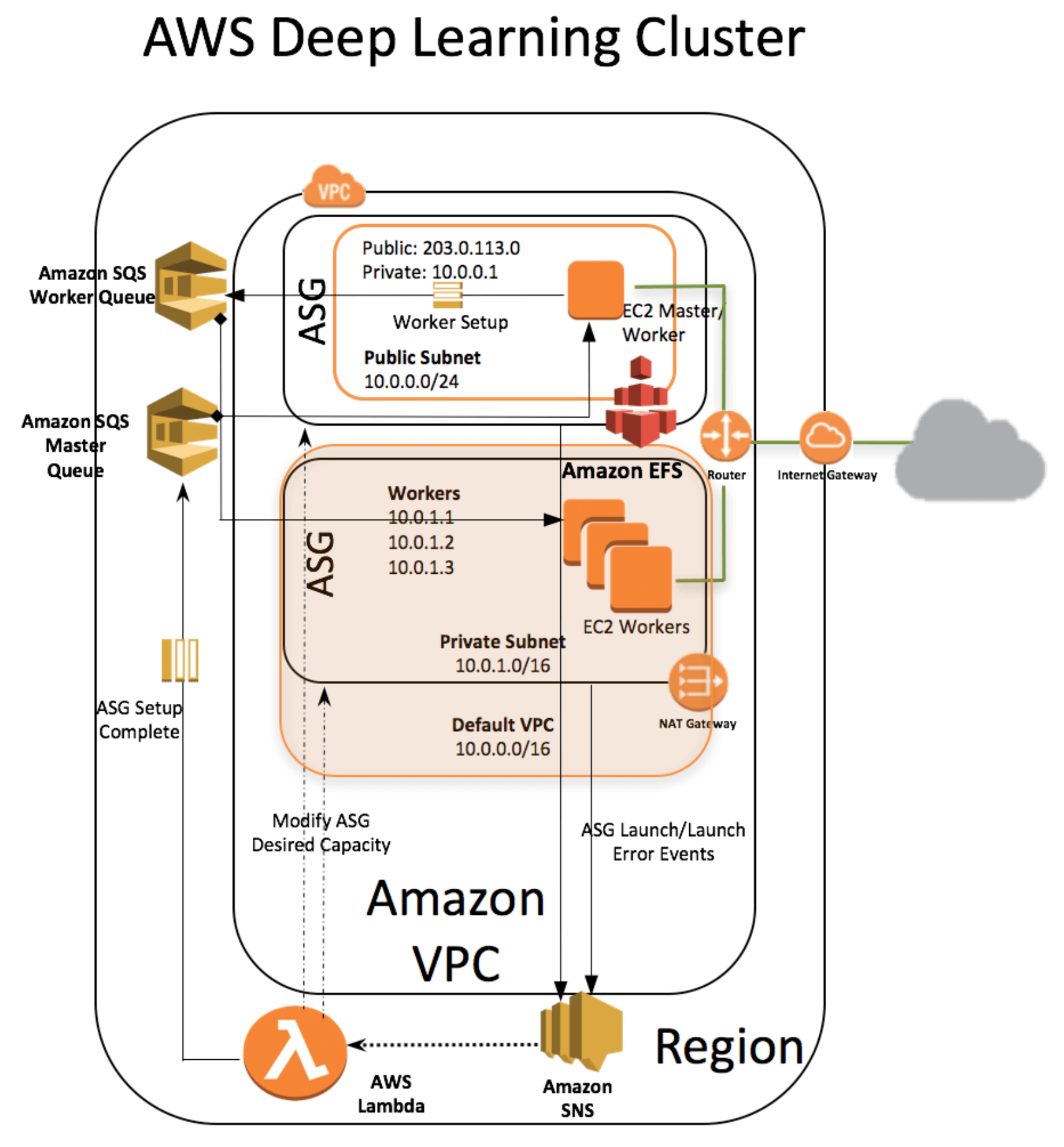
This can save you from a lot of manual set up when a single instance isn’t enough for your machine learning needs.
Amazon SageMaker
Amazon Sagemaker is new machine learning service that was announced at Amazon’s annual conference, re:Invent, in November 2017.
SageMaker fills a gap between Amazon ML and the Deep Learning AMIs. While Amazon ML is extremely easy to use, it has a limited number of models available in Amazon ML. On the other hand, Deep Learning AMIs give you complete freedom in training and modeling but require infrastructure maintenance and intimate data science knowledge. SageMaker provides almost as much flexibility as Deep Learning AMIs but in an easy to use, fully managed service.
SageMaker provides a fully managed service for machine learning from data exploration to model hosting. SageMaker can access data in S3, and it includes many common machine learning algorithms that are built-in. You also have the flexibility to fully customize algorithms using the Apache MXNet or Tensorflow frameworks. Once you build your model, using SageMaker you can train it with a single click that automatically scales up compute infrastructure to easily handle up to petabytes of data. The following infographic summarizes how SageMaker works:

AWS Machine Learning Research Awards
While not a cloud service per se, a notable mention in this list is the AWS Machine Learning Research Awards program. Machine learning research conducted at a university can be eligible for awards that include funding, AWS credits, access to AWS training resources, and an invitation to present your work at a seminar at AWS headquarters!
Conclusion
AWS has a variety of tools available for medical research and applications. This post focused on some of the machine learning services that are available:
- Amazon Machine Learning: A fully managed, easy-to-use service for building classification and regression models from data
- Amazon Deep Learning AMIs: A set of machine images that come pre-installed with all the most popular machine learning frameworks
- Amazon SageMaker: A fully managed service for end-to-end machine learning from data exploration to model hosting
If this post has sparked a machine learning research question in your mind, you can consider applying for an AWS Machine Learning Research Award. For a comprehensive look at the entire machine learning ecosystem in AWS, watch the Machine Learning on AWS Learning Path on Cloud Academy.