![]()
With Cloud Computing replacing layer after layer of server room hardware with virtual servers, what if you could virtualize the servers themselves out of existence? In a way, this is AWS Lambda.
It’s not uncommon to require your cloud-based apps to wake up and deliver some functionality when triggered by external events, but designing the process can be complicated. For example, I might need my application to respond every time there’s a change to the objects in one of my S3 buckets. Normally, I would configure some kind of service bus (in AWS, that would be SQS) to listen for S3 change notification, so that my app code, which is listening to SQS, can respond. All that can certainly work well. But managing the code and compute resources carries a significant operating overhead.
To address such challenges, Amazon created AWS Lambda, a service that can run your code in response to events and automatically manage the compute resources for you.
Events that can trigger a Lambda function
You can configure these events to trigger Lambda functions:
- Table updates in Amazon DynamoDB.
- Modifications to objects in S3 buckets.
- Notifications sent from Amazon SNS.
- Messages arriving in an Amazon Kinesis stream.
- AWS API call logs created by AWS CloudTrail.
- Client data synchronization events in Amazon Cognito.
- Custom events from mobile applications, web applications, or other web services.
AWS Lambda works using one of two event models: a push event model, or a pull event model. Lambda functions can be written in either JavaScript (or Node.js) and Java (Java 8 compatible).
How is AWS Lambda different from Amazon’s Elastic Beanstalk or EC2 Container Service?
When I first read about AWS Lambda I was confused. I wasn’t sure whether it was another PaaS (Platform as a Service) or a Docker-like container service like AWS ECS. In both those cases, developers push their code, and the rest (including compute deployment and application container provisioning) is taken care of by the service. So what’s all the fuss about Lambda?
But I eventually became aware of some key differences that help differentiate Lambda from all the others. Look more closely at Amazon’s EC2 Containers. Even though containers are highly scriptable, you are still responsible for maintaining them through their lifecycles. Since ECS only provides runtime execution services, everything else is in your hands. Lambda functions, on the other hand, are far more self-sufficient. Therefore, while Lambda has some features in common with EC2 Containers, it’s obviously much more than that.
Ok. If it’s not a container service, then perhaps it’s a platform like Elastic Beanstalk? Clearly not. Though Lambda does provide a kind of platform for developers, it’s much simpler than Beanstalk. Once your Lambda application is deployed, for instance, it can’t be accessed from the public network – unlike Beanstalk apps which can be accessed via their REST endpoints.
So in short, Lambda inherited some features from the EC2 Container Service and others from Elastic beanstalk, but it’s conceptually distant from both.
What does AWS Lambda do?
Now that we’ve got a bit more clarity about what AWS Lambda is, we can discuss ways to use it. Here are some common needs:
- Application developers writing event-driven applications want seamless integration between their AWS-based applications.
- Streaming data from AWS services like Kinesis and Dynamo DB needs processing.
- AWS Lambda can be configured with external event timers to perform scheduled tasks.
- Logs generated by AWS services like S3, Kinesis, and dynamoDB can be dynamically audited and tracked.
It might be helpful to take these Lambda features into account as you decide if this service is right for your project:
- AWS Lambda works only within the AWS ecosystem.
- AWS Lambda can be configured with external event timers, and can, therefore, be used for scheduling.
- Lambda functions are stateless, so they can quickly scale.
- More than one Lambda function can be added to a single source.
- AWS Lambda is fast: it will execute your code within milliseconds.
- AWS Lambda manages all of the compute resources required for your function and also provides built-in logging and monitoring through CloudWatch.
Watch this short video – taken from Understanding AWS Lambda to Run & Scale your code Course – to get a general understanding of how to run and scale your code with AWS Lambda.
Getting Started with AWS Lambda and DynamoDB
Now let’s get our hands dirty with a simple project using AWS Lambda and DynamoDB – AWS’s in-house NoSQL database. DynamoDB will be the source of our trigger and Lambda will respond to those changes. We will use node.js to write our function.
Here’s how it will work: if there is any change in a specified DynamoDB table, it should trigger a function that will print the event details. Let’s take it step-by-step:
1. Create a Lambda Service
- Login to the AWS console
- Click on Lambda

- You will be asked to select a blueprint. Blueprints are sample configurations of event sources and Lambda functions. You can ignore this by clicking on skip.


- Provide Lambda with some basic details as shown below and paste the Node.js code that you want to be triggered automatically whenever a new item is added in dynamoDB. Also, make sure the Role you select has all the required permissions.

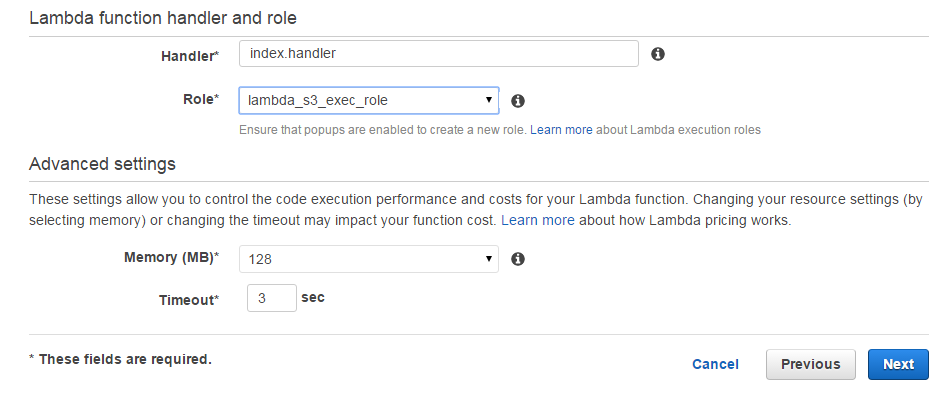
Note: The selected role should have the following policy attached to it:

- Verify the details in the next screen and click Create Function.
- Now, if you select the Lambda service you’ve created and click the Event Sources tab, there will be no records. But there should be an entry pointing to the source to which the Lambda function will respond. In our case its dynamo DB.
2. Create a DynamoDB table
Follow these steps to create a new Dynamo DB table:
- Login to the AWS console.
- Select DynamoDB.
- Click Create Table and fill out the form that will appear as below:

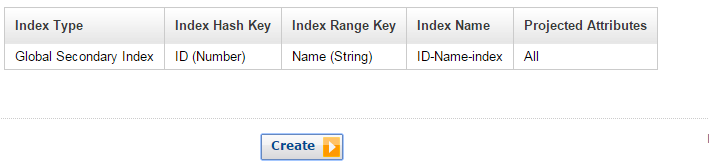
- Click Continue and, again, enter appropriate details into the form. Then click “Add Index to Table” as shown.

- Once your index has been created, you can verify it under Table Indexes.

- Clicking Continue will generate this screen:

We don’t need to make any changes, just click Continue. In the next screen, un-check the “Use Basic Alarms ”check box (assuming you don’t need any notifications).

- Click Continue once again and you will see a verification screen. Verify that everything looks the way it should and click Create.

- Now select your new table. Go to the Streams tab and associate it with the Lambda function that you created in Step 1.

Once your Lambda function is associated, you will see its entry in Event Sources tab of the Lambda service page.

- Now go to your DynamoDB table and add a new item. In our example, we added an item with the ID “10” and the Name “My First Lambda service is up and running”. Once the item is added and saved, our Lambda service should trigger the function. This can be verified by viewing the Lambda logs. To do that, select the Lambda service and click on the Monitoring tab. Then click View Logs in CloudWatch.

- Select the Log Group and check the log.

The output will be something like this:

So you have successfully configured and executed an AWS Lambda function! Now, your homework is to play around with generating other functions triggered by other sources.
If you want to get a deepen your knowledge on serverless, check out Cloud Academy’s Getting Started with Serverless Computing on AWS Learning Path.
Have any thoughts or comments? Join the discussion below.