![]()
What is Amazon Machine Learning and how does it work
“Amazon Machine Learning is a service that makes it easy for developers of all skill levels to use machine learning technology.”
UPDATES:
- Cloud Academy has now released a full course on Amazon Machine Learning that covers everything from basic principles to a practical demo where both batch and real-time predictions are generated.
- In October, I published a post on Amazon Mechanical Turk: help for building your Machine Learning datasets.
After using AWS Machine Learning for a few hours I can definitely agree with this definition, although I still feel that too many developers have no idea what they could use machine learning for, as they lack the mathematical background to really grasp its concepts.
Here I would like to share my personal experience with this amazing technology, introduce some of the most important, and sometimes misleading, concepts of machine learning, and give this new AWS service a try with an open dataset in order to train and use a real-world AWS Machine Learning model.
Luckily, AWS has done a great job in creating documentation that makes it easy for anyone to understand what machine learning is, when it can be used, and what you need to build a useful model.
You should check out the official AWS tutorial and its ready-to-use dataset. However, even if you follow through each step and produce a promising model, you may still feel like you’re not yet ready to create your own.
AWS Machine Learning tips
In my personal experience, the most crucial and time-consuming part of the job is defining the problem and building a meaningful dataset, which actually means:
- Making sure you know what you are going to classify/predict
- Collecting as much data as you can about the context without making too many assumptions on what is and isn’t relevant
The first point may seem trivial, but it turns out that not every problem can be solved with machine learning, even AWS Machine Learning. Therefore, you will need to understand whether your scenario fits or not.
The second point is important as well, since you will often discover unpredictable correlations between your input data (or “features”) and the target value (i.e. column you are trying to classify or predict).
You might decide to discard some input features in advance and somehow, inadvertently, decrease your model’s accuracy. On the other hand, deciding to keep the wrong column might expose your model to overfitting during the training and therefore weaken your new predictions.
For example, let’s say that you are trying to predict whether your registered users will pay for your product or not, and you include their “gender” field in the model. If your current dataset mostly contains data about male users, since very few females have signed up, you might end up with an always-negative prediction for every new female user, even though it’s not actually the case.
In a few words, overfitting simply means creating a model that is too specific to your current dataset and will not behave well with new data. Naturally, this is something you want to avoid.
That’s why you should always plan an evaluation phase where you split your dataset into two segments. The first one will be used to train the model. Then, you can test the model against the second segment of data and see how it behaves. A good model will be able to correctly predict new values. And that’s the magic we want!
Here are a few use cases, ranging from typical start-up requirements to more advanced scenarios:
- Predict whether a given user will become a paying customer based on her activities during the first day/week/month.
- Detect spammers, fake users, or bots in your system based on website activity records.
- Classify a song genre (rock, blues, metal, etc), based only on signal-level features.
- Recognize a character from a plain image (also known as OCR).
- Detect, based on accelerometer and gyroscope signals, whether a mobile device is standing still, moving (upstairs or downstairs), or how it is positioned (vertically or horizontally), etc.
All of these problems share a common assumption: You need to predict something “completely unknown” at runtime, but you have enough Ground Truth data (i.e. labeled records) and computing power to let Machine Learning solve the problem for you.
What AWS Machine Learning will do for your Organization
If you have ever built a classification model yourself, you know that you should carefully choose your model type based on your specific use case. AWS Machine Learning is quite powerful in this regard because it automatically trains and tests a lot of complex models, tuned with different parameters so that the best one will be chosen for the final evaluation. In fact, this will generally be the one you would usually end up figuring out by hand through trial and error.
Of course, AWS machine Learning will also handle all of your input normalization, dataset splitting, and model evaluation work. In fact, as long as you provide a valid data source, AWS Machine Learning can solve most of your low-level problems.
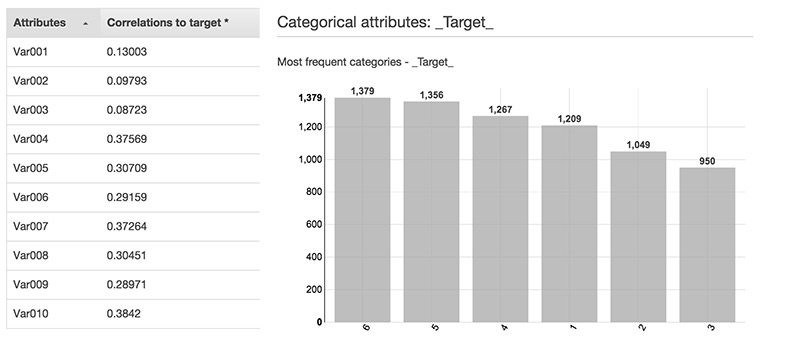
Even before training and evaluating your model, you can analyze your data source to better understand the often hidden correlations within your data. Indeed, in the Datasource attributes section, you can find the values distribution of all your columns, and clearly see which of them contribute more in defining your target value.
For example, you will probably generate a completely useless model if there is no correlation at all between features and target. So, before spending your time and money in the actual model training and evaluation task, you always want to have a look at these statistics. The whole process can take up to 30 minutes, even without considering the S3 upload!
A real use case: Human Activity Recognition
There are plenty of open datasets for machine learning provided by public institutions such as University of California, MLdata.org, and deeplearning.net. One of them might be a good starting point for your use case. You will need to adapt their input format to the kind of simple csv file AWS Machine Learning expects and understand how the input features have been computed so that you can actually use the model with your own online data to obtain predictions.
I found a very interesting dataset for HAR (Human Activity Recognition) based on smartphone sensors data. It is freely available here. This dataset contains more than 10,000 records, each defined by 560 features and one manually labeled target column, which can take one of the following values:
- 1 = walking
- 2 = walking upstairs
- 3 = walking downstairs
- 4 = sitting
- 5 = standing
- 6 = lying down
The 560 features columns are the input data of our model and represent the time and frequency domain variables obtained by the accelerometer and gyroscope signals. Since the target column can take more than two values, this is known as a multi-class problem (rather than a simpler binary problem). You can find more information about these values in the downloadable .zip file.
I can’t even imagine how mobile applications may actually use this kind of data. Perhaps they want to gain insight into app usage. Or perhaps they can track daily activity patterns in order to integrate them with your fitness daily report.
Preparing the Datasource csv file
This dataset was not formatted the way AWS Machine Learning expected. The typical notation in the ML field indicates the input matrix as X and the output labels as Y. Also, the usual 70/30 dataset split has already been performed by the dataset authors (you will find four files in total), but in our case, AWS Machine Learning will do all of that for us, so we want to upload the whole set as one single csv file.
I coded a tiny python script to convert the four matrix-formatted files into a single comma-separated file. This will be the input data of our Datasource.
from itertools import izip
import re
output_file = 'dataset.csv'
input_files = {
'train/X_train.txt': 'train/y_train.txt',
'test/X_test.txt': 'test/y_test.txt'
}
def getOutputLines(filenames):
for X,y in filenames.iteritems():
with open(X) as Xf, open(y) as yf:
for Xline, yline in izip(Xf, yf):
Xline = re.sub(' +', ' ', Xline).strip()
yield ','.join([yline.strip()] + Xline.split(' ')) + "\n"
with open(output_file, 'w+') as f:
for newline in getOutputLines(input_files):
f.writelines(newline)
Luckily, as a Datasource input, you can either use a single S3 file or a set of files with the same schema, so I decided to split my large file (~90MB) into smaller files of 1,000 records each and uploaded them to S3. Note that I couldn’t have uploaded the raw dataset files directly, as their schema is not coherent and not comma-separated.

Data manipulation and massaging is a typical step of your pre-training phase. The data might come from your database or your analytics data warehouse. You will need to format and normalize it, and sometimes create complex features (via aggregation or composition) to improve your results.
Training and evaluating the model
The process of creating your datasource, training, and evaluating your model is fairly painless with AWS Machine Learning, as long as your input data is well formatted. Don’t worry: If it’s not, you will receive an error during the Datasource creation. Everything will automatically stop if more than 10K of invalid records are detected.
In our case, everything should go pretty smoothly, even if kind of slowly, until the model is created and the first evaluation is available. At this point, it will show your model’s F1 score. The F1 score is an evaluation metric (0 to 1) that takes into account both precision and recall. With the given dataset, I got a score of 0.92, which is pretty good.

In addition to the score, you are also shown an evaluation matrix. The evaluation matrix is a graphical representation of your model behavior with the testing set. If your model works fine, you should find a diagonal pattern, meaning that the records belonging to the N class have been correctly classified as N, at least most of the time.
In a general scenario, some classes are easier to guess than others. In our case, the classes 1, 2, and 3 (the three walking classes) are pretty similar to each other, as well as 4 and 5 (sitting and standing). From the table, I can see that the most difficult class to guess is 5 (standing): in 13% of cases it will be classified as 4 (sitting). On the other hand, the class 2 (walking upstairs) is easy to guess (with almost 95% precision), but it might be wrongly classified as 1, 3, 4, or 5.
Based on this data, you might decide to enrich your dataset. for example we could add more “standing” records to help the model distinguish it from “sitting.” Or we might even find out that our data is wrong or biased by some experimental assumptions, in which case we’ll need to come up with new ideas or solutions to improve the data (i.e. “how tall was the chair used to record sitting positions based on the average person’s height?” etc).
How to use the model in your code
Now we have our machine learning model up and running and we want to use it on a real-world app. In this specific case, we would need to sit down and study how those 560 input features have been computed, code the same into our mobile app, and then call our AWS Machine Learning model to obtain an online prediction for the given record.
In order to simplify this demo, let’s assume that we have already computed the features vector, we’re using python on our server, and we have installed the well known boto3 library.
All we need to obtain a new prediction is the Model ID and its Prediction Endpoint. First of all, we need to enable the ML model for online predictions. We simply click on “Enable real time predictions” and wait for the endpoint to be available, which we will retrieve via API.

Note: Since I had more than 500 input columns I didn’t really take the time to name all of them, but when you have only a few input features it would definitely be a good idea. That way, you’ll avoid having to deal with meaningless input names such as “Var001”, “Var002.” In my python script below, I am reading the features record from a local file and generating names based on the column index (you can find the full commented code and the record.csv file here).
import boto3
from boto3.session import Session
session = Session(aws_access_key_id='YOUR_KEY', aws_secret_access_key='YOUR_SECRET_KEY')
machinelearning = session.client('machinelearning', region_name='YOUR_REGION')
model_id = 'YOUR_MODEL_ID'
labels = {'1': 'walking', '2': 'walking upstairs', '3': 'walking downstairs', '4': 'sitting', '5': 'standing', '6': 'laying'}
try:
model = machinelearning.get_ml_model(MLModelId=model_id)
prediction_endpoint = model.get('EndpointInfo').get('EndpointUrl')
with open('record.csv') as f:
record_str = f.readline()
record = {}
for index,val in enumerate(record_str.split(',')):
record['Var%03d' % (index+1)] = val
response = machinelearning.predict(MLModelId=model_id, Record=record, PredictEndpoint=prediction_endpoint)
label = response.get('Prediction').get('predictedLabel')
print("You are currently %s." % labels[label])
except Exception as e:
print(e)
The record is passed to our model and evaluated in real time (synchronously). You will obtain a Prediction object.
{
'Prediction': {
'predictedLabel': '2',
'predictedScores': {
'1': 2.609832350231045e-09,
'3': 5.4868586119027896e-08,
'2': 0.999945878982544,
'5': 5.999675582735176e-13,
'4': 5.4045554861659184e-05,
'6': 5.1530719795411795e-12
},
'details': {
'PredictiveModelType': 'MULTICLASS',
'Algorithm': 'SGD'
}
},
'ResponseMetadata': {
'HTTPStatusCode': 200,
'RequestId': '8525850d-ec68-11e4-9306-034326bf643c'
}
}
The field we need is predictedLabel. It represents the classified result based on our input. Note that we also get a probability measure for each class. In this case, the predicted class has a greater than 99% probability of being correct. These statistics could be incredibly useful even when the given prediction is not reliable enough. In those cases, we might inspect the other classes’ degree of reliability and decide to switch to our own prediction, based on the context assumptions.
An alternative solution could be storing a larger set of records (i.e. one minute’s worth of our sensors’ signals) and call the create_batch_prediction method. This API resource expects a set of observations as input and will asynchronously generate one prediction for each record into a given S3 bucket.
That’s it! You can use the predicted value to provide real-time feedback on the device, or store it and use it to generate your insights, etc. I am not focusing on the specific software architecture, as this will work just as well using a wide range of alternative profiles as long as you use the mentioned API correctly.
Is your Team ready for AWS Machine Learning?
While there are a million use cases with datasets unique to a variety of specific contexts, AWS Machine Learning successfully manages the process to allow you to focus just on your data, without wasting your time trying tons of models and dealing with boring math.
I am personally very curious to see how this service will evolve and how AWS users will exploit its features. Moreover, I would like to see how AWS will handle another typical need: Keeping the model updated with new observations. At the moment this is quite painful, as you would need to upload a brand new source to S3 and go through the whole training/testing process every time, ending up with N models, N evaluations, and N*3 data sources on your AWS Machine Learning dashboard.
Have you found any useful datasets? How are you going to use AWS Machine Learning? Let us know what you think and how we can help you improve your models.
In the meantime, I’d like to invite you to Cloud Academy to try our AWS Machine Learning Hands-on Lab. You can practice with the above-mentioned concepts and explore Amazon ML on the real AWS Console. If you’re new to Python, Cloud Academy offers an Introduction to Python Learning Path that guides you through the background and basics of Python so you get you the skills and knowledge you need to get started quickly as possible.